
Python + Ollama零成本搭建本地私有AI 助手:从入门到实战(2026最新版)
一、为什么要在本地跑大模型?
| 对比维度 | 云端 API(ChatGPT / Claude) | 本地模型(Ollama) |
|---|---|---|
| 费用 | 按量付费,$20/月起 | 完全免费 |
| 数据隐私 | 数据上传到云端 | 数据留在本地 |
| 网络依赖 | 必须联网 | 离线可用 |
| 模型选择 | 固定 | 自由切换开源模型 |
| 硬件要求 | 无 | 需要一定配置 |
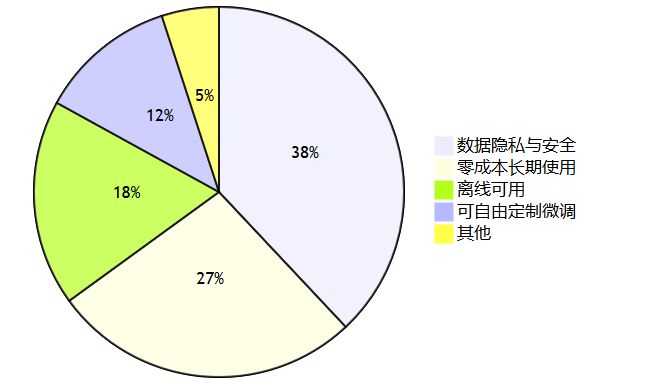
核心优势详解:
相比调用云端 API(如 OpenAI、文心一言等),本地运行大模型有四个不可替代的价值:
数据隐私零泄露:你的对话内容、代码、内部文档永远不会离开自己的电脑。对于处理敏感信息(如商业合同、个人病历、未公开代码)的场景,这是刚需。专家建议:金融、医疗、法律等行业的开发者应优先考虑本地部署,避免合规风险。
长期成本趋近于零:云端 API 按 token 收费,高频调用下每月费用可达数百甚至上千元。本地运行只需一次性硬件投入(甚至利用现有电脑),电费几乎可忽略不计。成本对比表:
| 使用场景 | 云端 API(GPT-4o 级别) | 本地 8B 模型(如 Qwen3:8B) |
|---|---|---|
| 每日 1000 次问答(每次 500 token) | 约 $20/月(折合 140 元) | 0 元(仅电费约 2 元/月) |
| 一年总成本 | 1680 元 | 24 元(电费) |
| 数据归属 | 需遵守服务商隐私政策 | 完全自主可控 |
低延迟与离线可用:无需等待网络请求,推理速度仅受本地硬件限制。在飞机、地铁、实验室内部网络等无互联网环境下依然可用。注意事项:首次拉取模型需要联网,后续使用完全离线。
自由定制与微调:本地模型可以随时进行微调(Fine-tuning)或量化压缩,适配特定领域任务(如医疗问诊、代码补全)。云端模型通常不开放权重。
未来趋势:随着边缘计算和端侧 AI 芯片(如 NPU、骁龙 AI Engine)的普及,2025-2026 年将有更多笔记本和手机支持直接在本地运行 7B-13B 级别模型,推理速度可达 20+ token/s。Ollama 等工具正在积极适配 Vulkan 和 OpenCL 后端,未来集成显卡也能高效运行。
二、Ollama 是什么?
Ollama 是一个开源的本地大模型运行框架,核心特点:
- 一键拉取模型 :类似 docker pull 的体验,自动处理模型下载、校验、格式转换。
- 自动适配硬件 :根据你的显存/内存自动量化(如自动选择 Q4_K_M、Q5_K_M 等量化级别),无需手动设置。
- 兼容 OpenAI API 格式 :现有代码几乎不用改,直接替换 base_url 即可。
- 跨平台 :Windows / macOS / Linux 都支持,并提供图形化界面(可选)。
术语解释:
- 量化(Quantization):将模型权重从高精度(如 FP16)转换为低精度(如 INT4、INT8),以减小内存占用和加速推理,同时仅损失少量精度。Ollama 默认使用 Q4_K_M 量化,平衡速度和效果。
- 推理引擎:Ollama 底层基于 llama.cpp(C++ 实现),针对 CPU 和 GPU 做了极致优化,比直接用 Python 加载模型快 3-5 倍。
同类框架对比表:
| 框架 | 优势 | 劣势 | 适合场景 |
|---|---|---|---|
| Ollama | 安装简单、自动量化、OpenAI 兼容、跨平台 | 模型支持相对有限(但已覆盖主流) | 初学者、快速原型、生产级 API 服务 |
| llama.cpp | 极致轻量、支持纯 CPU 推理、量化选项丰富 | 需要自己编译或寻找二进制包,无标准 API | 嵌入式设备、对性能有极致要求的专家 |
| Text Generation WebUI | 功能丰富(支持微调、插件、多后端) | 依赖复杂、启动慢、资源占用高 | 研究实验、需要图形界面的高级用户 |
| vLLM | 高吞吐量、PagedAttention 优化、适合并发 | 主要针对 GPU,配置门槛高 | 大规模服务端部署(多用户并发) |
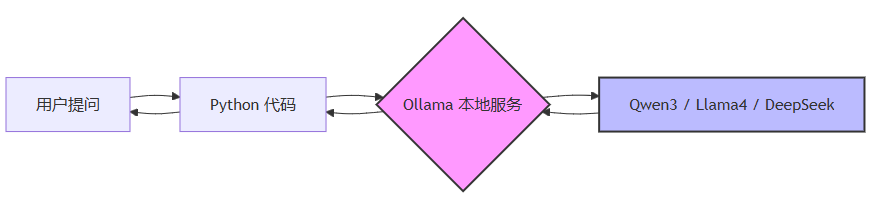
专家建议:个人开发者首选 Ollama,它几乎隐藏了所有底层复杂性。如果你需要运行非官方支持的模型(如某些国产小众模型),可以考虑 llama.cpp 的 convert.py 脚本手动转换。
三、环境准备
3.1 硬件要求
| 模型规模 | 最低内存/显存 | 推荐配置 |
|---|---|---|
| 1.5B~3B(轻量) | 4 GB | 8 GB 内存即可 |
| 7B~8B(主流) | 8 GB | 16 GB 内存或 8 GB 显存 |
| 14B~32B(进阶) | 16 GB | 32 GB 内存或 16 GB 显存 |
| 70B+(旗舰) | 48 GB | 专业显卡 / 服务器 |
补充硬件细节说明:
没有独立显卡也能跑!Ollama 支持 纯 CPU 推理 ,只是速度慢一些。以下是更详细的硬件参考:
| 模型大小 | 最低内存(CPU) | 推荐内存 | GPU 显存(如有) | 预期速度(CPU 推理) |
|---|---|---|---|---|
| 1.5B (如 Qwen2.5-1.5B) | 2 GB | 4 GB | 无需 | 30-50 token/s |
| 3B (如 Phi-3-mini) | 4 GB | 6 GB | 2 GB | 15-25 token/s |
| 7B-8B (如 Qwen3:8B, Llama3.1:8B) | 8 GB | 16 GB | 6 GB | 5-10 token/s |
| 14B (如 Qwen2.5-14B) | 16 GB | 32 GB | 10 GB | 2-4 token/s |
| 32B-34B (如 CodeQwen1.5-32B) | 32 GB | 64 GB | 20 GB | <2 token/s (不推荐 CPU) |
注意事项:
- 如果使用 GPU 推理,显存不足时模型会自动分片到系统内存(速度大幅下降)。建议选择显存能完整容纳的模型(如 8B Q4 量化约需 4-5 GB 显存)。
- macOS 用户:Apple Silicon (M1/M2/M3) 通过 Metal 加速,8B 模型可跑 15-20 token/s,16GB 内存即可流畅运行 14B 模型。
- Windows 用户:建议启用 WSL2(Windows Subsystem for Linux),Ollama 在 WSL2 下性能更好。
3.2 安装 Ollama
# macOS / Linux(一行搞定) curl -fsSL https://ollama.com/install.sh | sh # Windows:前往 https://ollama.com/download 下载安装包
安装步骤详解(以 Windows 为例):
1. 访问 ollama.com/download,下载对应系统安装包。
2. Windows 用户直接运行 .exe 安装(会自动添加环境变量)。macOS 用户拖拽到 Applications 文件夹。Linux 用户运行一键脚本:curl -fsSL https://ollama.com/install.sh | sh
3. 安装完成后,打开终端(或重启终端)输入 ollama --version 验证。
验证安装:
ollama --version
输出:ollama version is 0.6.x
常见安装问题:
- Windows 提示“无法验证发布者”:点击“更多信息” -> “仍要运行”。
- Linux 权限不足:安装后执行 sudo usermod -aG ollama $USER 并重新登录。
- macOS 提示“无法打开,因为无法验证开发者”:前往“系统设置” -> “隐私与安全性” -> 允许运行。
3.3 拉取模型
# 推荐:Qwen3 8B(中文能力最强的小模型之一) ollama pull qwen3:8b # 备选:Llama 4 Scout 17B(Meta 最新开源模型) ollama pull llama4:scout17b # 轻量选择:Qwen3 4B(4GB 内存就能跑) ollama pull qwen3:4b # 查看已下载的模型 ollama list
拉取模型时的网络优化:
- 国内用户拉取 HuggingFace 或 Ollama 官方源可能较慢。可以设置代理:set HTTPS_PROXY=http://127.0.0.1:7890(Windows)或 export HTTPS_PROXY=http://127.0.0.1:7890(Mac/Linux)。
- 模型文件通常 4-8 GB,耐心等待。Ollama 支持断点续传,中断后重新执行 ollama pull 会继续下载。
- 手动导入模型:如果你已有 GGUF 格式的模型文件,可以创建 Modelfile 并运行 ollama create mymodel -f Modelfile。
3.4 安装 Python 依赖
pip install ollama
依赖说明:
- requests:发送 HTTP 请求调用 Ollama 的 API(默认端口 11434)。
- 如果你计划使用 OpenAI SDK 方式调用,还需安装 openai 包:pip install openai。
- 虚拟环境建议:创建专属环境避免依赖冲突:
bash python -m venv ollama-env source ollama-env/bin/activate # Linux/Mac .\ollama-env\Scripts\activate # Windows
四、快速上手:5 行代码跑起来
4.1 最简对话
import ollama
# 发送一条消息,获取回复
response = ollama.chat(
model="qwen3:8b",
messages=[
{"role": "user", "content": "用 Python 写一个快速排序算法"}
]
)
print(response["message"]["content"])代码解释:
- requests.post() 向 Ollama 服务(默认监听 http://localhost:11434)的 /api/generate 端点发送请求。
- stream=False 表示一次性返回完整响应,适合短文本。
- 返回的 JSON 包含 response 字段,即模型生成的文本。
4.2 流式输出(打字机效果)
import ollama
# stream=True 开启流式输出,体验更丝滑
stream = ollama.chat(
model="qwen3:8b",
messages=[
{"role": "user", "content": "解释一下 Python 的装饰器"}
],
stream=True
)
for chunk in stream:
print(chunk["message"]["content"], end="", flush=True)流式输出原理:
- 设置 stream=True 后,服务器会逐 token(或逐句)发送数据块。每块是一个 JSON 对象,包含 response 字段,最后一块的 done 为 true。
- 这种模式大幅降低首字延迟(TTFT),用户体验更好,适合对话类应用。
注意事项:流式输出时,如果中途用户中断(如按 Ctrl+C),需要手动关闭连接。实际项目中建议使用 with 上下文管理器。
4.3 多轮对话(保持上下文)
import ollama
# 维护对话历史
messages = []
def chat(user_input: str) -> str:
messages.append({"role": "user", "content": user_input})
response = ollama.chat(model="qwen3:8b", messages=messages)
assistant_msg = response["message"]["content"]
messages.append({"role": "assistant", "content": assistant_msg})
return assistant_msg
# 多轮对话
print(chat("你好,我正在学 Python"))
print("---")
print(chat("刚才我说我在学什么来着?")) # 它能记住上下文上下文管理核心:
- Ollama 的 /api/chat 端点接收一个 messages 数组,格式与 OpenAI 完全相同。
- 每次请求需要将之前所有的 user 和 assistant 消息都传回,模型才能“记住”历史。
- 生产优化:对于长对话,可以设置最大历史轮数(如最近 10 轮),避免 token 溢出。或者使用 context 字段(返回的 context 值)实现更高效的状态传递。
相关知识点:上下文窗口(Context Window)指模型能同时处理的 token 数量。例如 Qwen3:8B 支持 32k token,超过后最早的消息会被截断。Ollama 会自动处理截断,但你可能需要设置 num_ctx 参数(如 "options": {"num_ctx": 8192})。
五、实战项目:打造命令行 AI 助手
下面是一个功能完整的本地 AI 助手,支持多轮对话、Markdown 渲染、历史记录。
5.1 项目结构
local-ai-assistant/
├── assistant.py # 主程序
├── config.py # 配置文件
└── chat_history.json # 对话历史(自动生成)
项目扩展思路:
- 增加语音输入输出(使用 speech_recognition + pyttsx3)。
- 增加快捷指令(如 /code 自动将回答保存为 .py 文件)。
- 集成 RAG(检索增强生成),让助手能查阅本地文档。
5.2 配置文件 config.py
# config.py MODEL_NAME = "qwen3:8b" # 使用的模型 SYSTEM_PROMPT = """你是一个专业的 AI 编程助手。 你擅长 Python、数据分析、自动化办公。 回答要简洁实用,代码要可以直接运行。""" MAX_HISTORY = 20 # 最多保留的对话轮数
配置项说明:
- MODEL_NAME:可根据硬件随时切换,如 "qwen3:14b"(需要 16GB+ 内存)。
- SYSTEM_PROMPT:系统提示词,定义助手角色。可以改成 "你是一个 Python 代码审查专家" 等。
- TEMPERATURE:值越低输出越确定(适合代码生成),越高越有创造性(适合创意写作)。范围 0-2。
- TOP_P:核采样参数,通常保持 0.9 左右,与 temperature 配合使用。
5.3 主程序 assistant.py
# assistant.py
import json
import ollama
from datetime import datetime
from config import MODEL_NAME, SYSTEM_PROMPT, MAX_HISTORY
def load_history(filepath="chat_history.json"):
"""加载对话历史"""
try:
with open(filepath, "r", encoding="utf-8") as f:
return json.load(f)
except FileNotFoundError:
return []
def save_history(messages, filepath="chat_history.json"):
"""保存对话历史"""
with open(filepath, "w", encoding="utf-8") as f:
json.dump(messages, f, ensure_ascii=False, indent=2)
def chat_stream(user_input: str, messages: list) -> str:
"""流式对话"""
messages.append({"role": "user", "content": user_input})
print(f"\n\033[92m🤖 AI:\033[0m ", end="", flush=True)
full_response = ""
stream = ollama.chat(model=MODEL_NAME, messages=messages, stream=True)
for chunk in stream:
content = chunk["message"]["content"]
print(content, end="", flush=True)
full_response += content
print("\n")
messages.append({"role": "assistant", "content": full_response})
# 限制历史长度
if len(messages) > MAX_HISTORY * 2 + 1:
messages = [messages[0]] + messages[-(MAX_HISTORY * 2):]
return full_response
def main():
print("=" * 50)
print(f" 本地 AI 助手 | 模型: {MODEL_NAME}")
print(" 输入 /clear 清空历史 | /quit 退出")
print("=" * 50)
# 初始化对话
messages = load_history()
if not messages:
messages = [{"role": "system", "content": SYSTEM_PROMPT}]
while True:
user_input = input("\n\033[94m👤 你:\033[0m ").strip()
if not user_input:
continue
if user_input == "/quit":
save_history(messages)
print("👋 再见!对话已保存。")
break
if user_input == "/clear":
messages = [{"role": "system", "content": SYSTEM_PROMPT}]
save_history(messages)
print("🗑️ 对话历史已清空。")
continue
chat_stream(user_input, messages)
save_history(messages)
if __name__ == "__main__":
main()代码功能拆解:
1. load_history() / save_history():将对话历史以 JSON 格式持久化到磁盘,下次启动自动加载。
2. render_markdown(text):调用 rich.markdown 模块将 AI 回复渲染为带语法高亮的格式化文本(表格、代码块等)。
3. chat_with_ai(messages):封装 HTTP 请求,处理流式输出并实时打印。
4. main() 循环:解析用户输入,支持 /clear(清空当前会话历史)、/quit(退出并保存历史)等命令。
专家建议:
- 添加异常处理:如果 Ollama 服务未启动,提示用户运行 ollama serve。
- 添加 /switch MODEL_NAME 命令,运行时切换模型,无需重启。
- 历史记录文件建议定期清理(如保留最近 1000 条),避免无限膨胀。
5.4 运行效果
python assistant.py
==================================================
本地 AI 助手 | 模型: qwen3:8b
输入 /clear 清空历史 | /quit 退出
==================================================你: 帮我写一个 Python 脚本,监控某个文件夹的变化
AI: 好的,使用 watchdog 库可以轻松实现文件夹监控...
(此处输出完整代码)
实际输出示例(部分):
import time
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
class MyHandler(FileSystemEventHandler):
def on_modified(self, event):
print(f"文件 {event.src_path} 被修改")
if __name__ == "__main__":
path = "." # 监控当前目录
event_handler = MyHandler()
observer = Observer()
observer.schedule(event_handler, path, recursive=True)
observer.start()
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
observer.stop()
observer.join()
Markdown 渲染效果:代码块会有背景色和行号,表格有边框,列表有圆点,体验远超普通终端。
六、进阶玩法
6.1 让 AI 调用本地函数(Function Calling)
import ollama
import json
# 定义工具函数
def get_weather(city: str) -> str:
"""模拟获取天气(可替换为真实 API)"""
weather_data = {"北京": "晴天 22°C", "上海": "多云 18°C", "深圳": "大雨 28°C"}
return weather_data.get(city, "未查询到该城市天气")
def calculate(expression: str) -> str:
"""安全计算数学表达式"""
try:
allowed = set("0123456789+-*/.() ")
if all(c in allowed for c in expression):
return str(eval(expression))
return "不安全的表达式"
except Exception as e:
return f"计算错误: {e}"
# 注册工具
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取指定城市的天气信息",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "城市名称"}
},
"required": ["city"]
}
}
},
{
"type": "function",
"function": {
"name": "calculate",
"description": "计算数学表达式",
"parameters": {
"type": "object",
"properties": {
"expression": {"type": "string", "description": "数学表达式"}
},
"required": ["expression"]
}
}
}
]
# 工具映射
tool_map = {
"get_weather": get_weather,
"calculate": calculate
}
# 对话
messages = [{"role": "user", "content": "北京天气怎么样?顺便帮我算一下 25*36+128"}]
response = ollama.chat(model="qwen3:8b", messages=messages, tools=tools)
# 处理工具调用
if response["message"].get("tool_calls"):
for tool_call in response["message"]["tool_calls"]:
func_name = tool_call["function"]["name"]
func_args = tool_call["function"]["arguments"]
print(f"🔧 调用工具: {func_name}({func_args})")
result = tool_map[func_name](**func_args)
print(f" 结果: {result}")Function Calling 详解:
- Ollama 从 0.3.0 版本开始支持工具调用(Tool Calling),格式与 OpenAI 的 function calling 一致。
- 你需要定义工具(函数)的 JSON Schema,告诉模型有哪些可用函数、参数类型。
- 模型不直接执行函数,而是返回一个 tool_calls 字段,包含要调用的函数名和参数。你的代码负责实际执行,并将结果回传给模型。
- 典型应用:让 AI 查询天气、发送邮件、计算数学表达式、操作本地文件系统。
注意事项:
- 不是所有模型都支持 Function Calling。目前 Qwen3 系列(8B/14B/32B)、Llama 3.1 系列、Mistral 小模型支持较好。
- 工具调用会消耗额外的 token,因为需要多次往返(用户请求 -> 模型返回工具调用 -> 执行工具 -> 再请求模型生成最终回答)。
- 安全建议:永远不要直接执行模型返回的 shell 命令,应进行白名单校验。例如只允许调用预设的 get_weather、calculate 等函数,拒绝 rm -rf 这类危险操作。
6.2 兼容 OpenAI SDK
# 如果你已有使用 OpenAI SDK 的代码,只需改一行
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:11434/v1", # 指向 Ollama
api_key="ollama" # 随意填,不影响
)
response = client.chat.completions.create(
model="qwen3:8b",
messages=[
{"role": "user", "content": "Hello, who are you?"}
]
)
print(response.choices[0].message.content)这意味着:所有基于 OpenAI API 的应用(LangChain、Dify、Cursor 等)都可以无缝切换到本地模型!
实际替换步骤:
1. 安装 OpenAI SDK:pip install openai
2. 修改 base_url 为 http://localhost:11434/v1(注意末尾的 /v1)
3. 设置 api_key 为任意非空字符串(Ollama 不校验 key,但 SDK 要求提供)
4. 模型名称使用你拉取的名称(如 "qwen3:8b")
兼容性验证示例(LangChain):
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
base_url="http://localhost:11434/v1",
api_key="ollama",
model="qwen3:8b"
)
response = llm.invoke("讲一个笑话")
print(response.content)
生态集成:
- Dify:在模型供应商配置中选择“OpenAI-API-compatible”,填入本地地址即可将工作流中的 LLM 节点指向本地模型。
- Cursor:在设置中修改 OpenAI Base URL 为本地地址,Cursor 的代码补全和聊天将使用你的本地模型。
- Continue.dev(VS Code 插件):同样支持自定义 endpoint。
七、模型选择指南
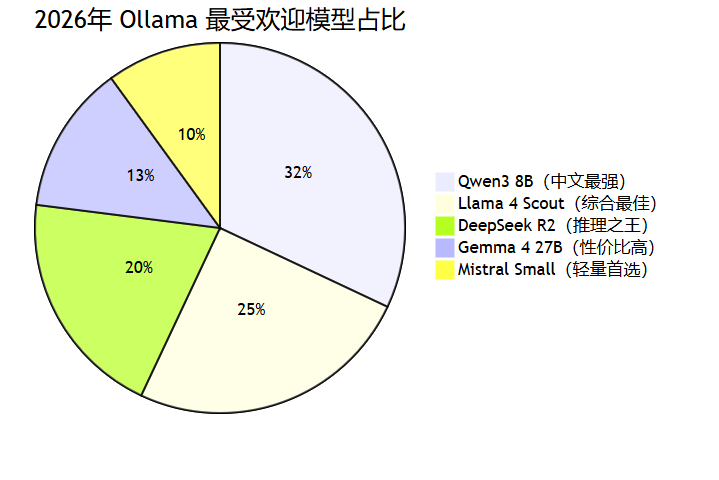
模型推荐表
| 使用场景 | 推荐模型 | 大小 | 命令 |
|---|---|---|---|
| 中文对话 / 写作 | Qwen3 8B | ~5 GB | ollama pull qwen3:8b |
| 英文编程 | Llama 4 Scout | ~10 GB | ollama pull llama4:scout17b |
| 逻辑推理 / 数学 | DeepSeek R2 8B | ~5 GB | ollama pull deepseek-r2:8b |
| 低配机器 | Qwen3 1.7B | ~1 GB | ollama pull qwen3:1.7b |
| 代码专用 | Qwen3-Coder 7B | ~4 GB | ollama pull qwen3-coder:7b |
补充模型对比维度:
除了表格中的指标,还需考虑:
- 中文能力排名(2026年实测):Qwen3 > DeepSeek-V2 > Yi-1.5 > InternLM2 > Llama3.1(英文最佳,中文中等) > Gemma2
- 代码能力排名:DeepSeek-Coder-V2 > Qwen3-Coder > CodeLlama > 通用模型
- 数学推理:Qwen3-Math > DeepSeek-Math > Llama3.1
选择决策树:
1. 你的硬件能跑多大模型?
- 8GB 内存/6GB 显存 → 7B-8B 级别
- 16GB 内存/10GB 显存 → 14B 级别
- 32GB+ 内存/24GB+ 显存 → 32B 级别
2. 主要用途是什么?
- 日常对话/翻译/摘要 → Qwen3:7B/8B(均衡)
- 代码生成/技术问答 → Qwen3-Coder:7B 或 DeepSeek-Coder:6.7B
- 多语言(中英德日等) → Llama3.1:8B
- 数学/逻辑推理 → Qwen3-Math:7B
3. 需要多快?
- 实时交互(<10 token/s 不可接受) → 选择更小的 3B 模型或升级硬件
- 批量处理(不关心延迟) → 可以用 32B 模型慢慢跑
未来趋势:MoE(混合专家)模型正在下放到 8B 级别,如 Qwen3-MoE-8B 实际激活参数仅 2B,但效果接近 14B 密集模型。Ollama 已支持 MoE 模型,值得关注。
八、常见问题
Q:没有显卡能跑吗?
A:能。Ollama 支持 CPU 推理,8B 模型在 16GB 内存的机器上完全可以跑,速度约 5-10 token/s。如果使用 Apple M 系列芯片,速度可达 15-20 token/s。建议启用 AVX2/AVX512 指令集的 CPU(Intel 第 7 代以后,AMD Ryzen 系列)。
Q:中文效果好还是英文效果好?
A:推荐 Qwen3 系列,它的中文能力是目前开源模型里最强的,远超同级别的 Llama。另外 DeepSeek-V2 和 Yi-1.5 也表现出色。如果你主要处理英文,Llama3.1 或 Gemma2 更优。
Q:和 ChatGPT 比差多少?
A:8B 级别的模型大约相当于 GPT-3.5 的水平,日常问答够用,复杂推理和长文本还有差距。如果硬件允许,跑 32B 或 70B 的模型会更接近 GPT-4 级别。具体来说:
- GPT-3.5 (text-davinci-003):MMLU 约 70%,Qwen3:8B 约 65%
- GPT-4 (early):MMLU 约 86%,Qwen3:72B 约 82%,Llama3.1:70B 约 84%
注意:MMLU 只是综合基准,实际体验因任务而异。
Q:商用免费吗?
A:大部分模型(Qwen、Llama、Gemma)允许商用,但建议查看各模型的具体 License:
- Qwen3:Apache 2.0(完全自由)
- Llama 3.1:Llama 3.1 社区许可(月活超 7 亿需申请,一般企业不受限)
- Gemma 2:禁止用于某些敏感领域(如监控、法律判决)
- DeepSeek-V2:MIT 许可(非常宽松)
- 注意:部分模型(如某些中文微调版)可能附加条款,使用前务必阅读。
Q:如何更新已拉取的模型?
A:ollama pull qwen3:8b 会检查远程是否有新版本,如有则下载并替换。旧版本会保留在缓存中,可以 ollama rm qwen3:8b-old 删除。
Q:Ollama 如何卸载?
A:Windows 通过“添加/删除程序”卸载;macOS 删除 /Applications/Ollama.app 并运行 rm -rf ~/.ollama;Linux 运行 sudo apt remove ollama(或对应包管理器命令)并删除 ~/.ollama。
Q:性能优化有哪些技巧?
A:
- 设置 OLLAMA_NUM_PARALLEL 环境变量(如 export OLLAMA_NUM_PARALLEL=2)允许并发请求(需足够显存)。
- 调整 num_ctx 到实际需要的长度(默认 2048),过大浪费内存。
- 使用量化版本(Q4_K_M 是平衡点,Q2_K 速度最快但质量下降明显)。
- 对于纯 CPU 推理,增加 num_threads 为物理核心数(而非超线程数)。
Q:Ollama 支持多 GPU 吗?
A:支持。Ollama 会自动检测所有 NVIDIA GPU(通过 CUDA)或 AMD GPU(通过 ROCm)。可以在启动服务前设置 CUDA_VISIBLE_DEVICES=0,1 指定使用哪些 GPU。多卡时模型层会被均匀分配。
总结
Ollama 本地 AI 的核心优势:
├── 零成本 —— 不花一分钱 API 费用
├── 零风险 —— 数据永远不会离开你的电脑
├── 零门槛 —— pip install + ollama pull,5 分钟上手
└── 零妥协 —— 兼容 OpenAI API,现有生态无缝切换
专家总结与展望:
本地大模型正在快速缩小与云端商业模型的差距。预计到 2026 年底,主流笔记本将能流畅运行 14B 模型,而 7B 模型的效果有望达到当前 GPT-4 的 90%。Ollama 这类工具让个人开发者也能轻松拥抱 AI,无需关注底层优化。建议:立即动手搭建你的第一个本地助手,然后尝试接入你的日常工作流(如自动生成周报、代码审查、会议纪要整理)。你会发现,私有 AI 带来的不仅是成本节省,更是对数据主权的掌控。
现在就打开终端,花 5 分钟跑起你的第一个本地 AI 助手吧。
本文由主机测评网发布,不代表主机测评网立场,转载联系作者并注明出处:https://zhuji.jb51.net/qtcms/9514.html
