
风暴:jemalloc、glibc与fork的致命邂逅,及其在AMD CPU上引发的系统性崩溃
本文深度复盘了一次发生在阿里云AMD Turin平台混部环境中的P0级硬件性能故障。故障表现为整机CPI飙升,在线与离线业务性能同时劣化。通过层层递进的排查,从TopDown微架构分析入手,结合内核、glibc、Python、jemalloc等多层代码分析,最终定位到根本原因为jemalloc与glibc ptmalloc在特定竞争条件(fork + hook失效)下混用,导致无效内存地址上的Split Lock操作,并在AMD硬件特性加持下升级为全局Bus Lock。文章不仅详细记录了完整的排查逻辑与技术细节,还提供了Split Lock的规避实践、跨平台差异分析以及完整的解决方案,为在新硬件平台上保障混部稳定性提供了极具价值的经验。
一、问题发现:大促前夜的性能惊雷
从8月底开始,集团新部署的大量AMD EPYC(代号“Turin”)服务器上频繁出现一种诡异现象:整机所有业务的CPI(Cycles Per Instruction,每条指令周期数) 会毫无征兆地从正常水平(低于1)瞬间飙升到3甚至4。
这是一个极为危险的信号。CPI是衡量CPU执行效率的核心指标,CPI飙升意味着CPU在“空转”,执行相同指令需要花费数倍的时钟周期。其直接影响是:
* 在线业务受损:由于指令周期变长,在线容器的CPU利用率也随之飙升3-4倍,导致应用响应延迟增加,性能严重劣化。
* 离线业务被压制:在线业务对CPU资源的异常抢占,进一步压制了同机混部的离线计算任务(如ODPS数据分析),形成“双输”局面。
问题背景与特殊性:此次故障发生在 “双11”大促备战的关键时期,且集中于承载大量核心业务的最新AMD EPYC平台。这类服务器的混部架构通常是:在宿主机上运行在线业务容器,同时通过一个Kata Container(袋鼠容器) 提供一个完整的虚拟机环境,用于运行ODPS离线计算任务,该虚拟机独占(vcpu核数等于宿主机核数)。问题的严重性和紧迫性使之被立即提升为最高优先级(P0)故障进行排查。
技术拓展:什么是CPI?
CPI是计算机体系结构中的关键性能指标,计算公式为 CPI = CPU时钟周期数 / 指令数。CPI越低,说明CPU效率越高。当CPI从0.8飙升至3.2,意味着CPU执行效率下降了75%,这是系统性性能故障的明确标志。
二、现象观察:全面劣化与反直觉特征
故障排查首先从现象入手,我们观察到了以下普遍规律:
1. 全面性劣化:在线业务容器的CPI和CPU利用率同步突增。
2. 链式反应:在线业务的异常资源占用,导致运行在Kata Container中的离线任务受到严重压制,业务性能整体受损。
3. 表象反常:根据以往经验,整机CPI上涨通常与内存带宽瓶颈或内存访问延迟增加相关。但本次故障的监控数据(如下图所示)却显示,在CPI飙升期间,内存带宽和延迟指标并未出现异常波动,这与常规判断相悖。
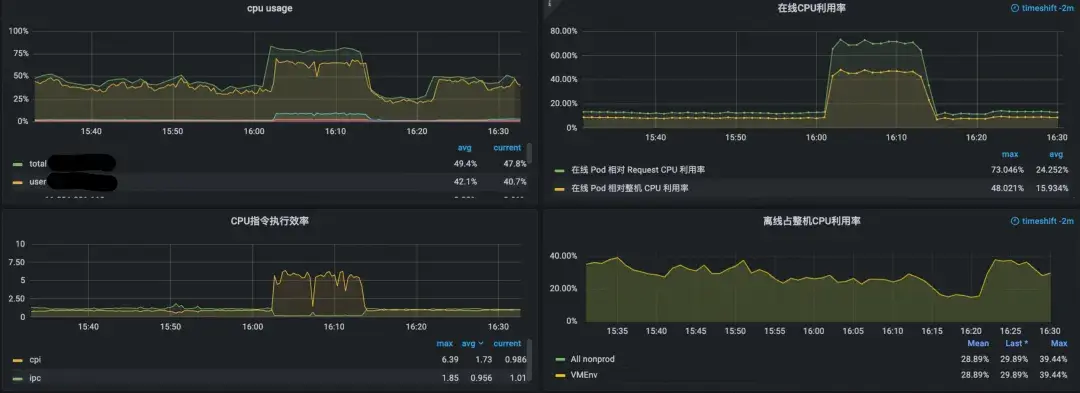
(图:故障期间内存带宽与时延指标正常,与CPI飙升形成反差)
进一步的精细化监控揭示了更细粒度的异常:
* 所有业务Pod的CPI均突增,表明问题影响范围是整机,而非单个应用。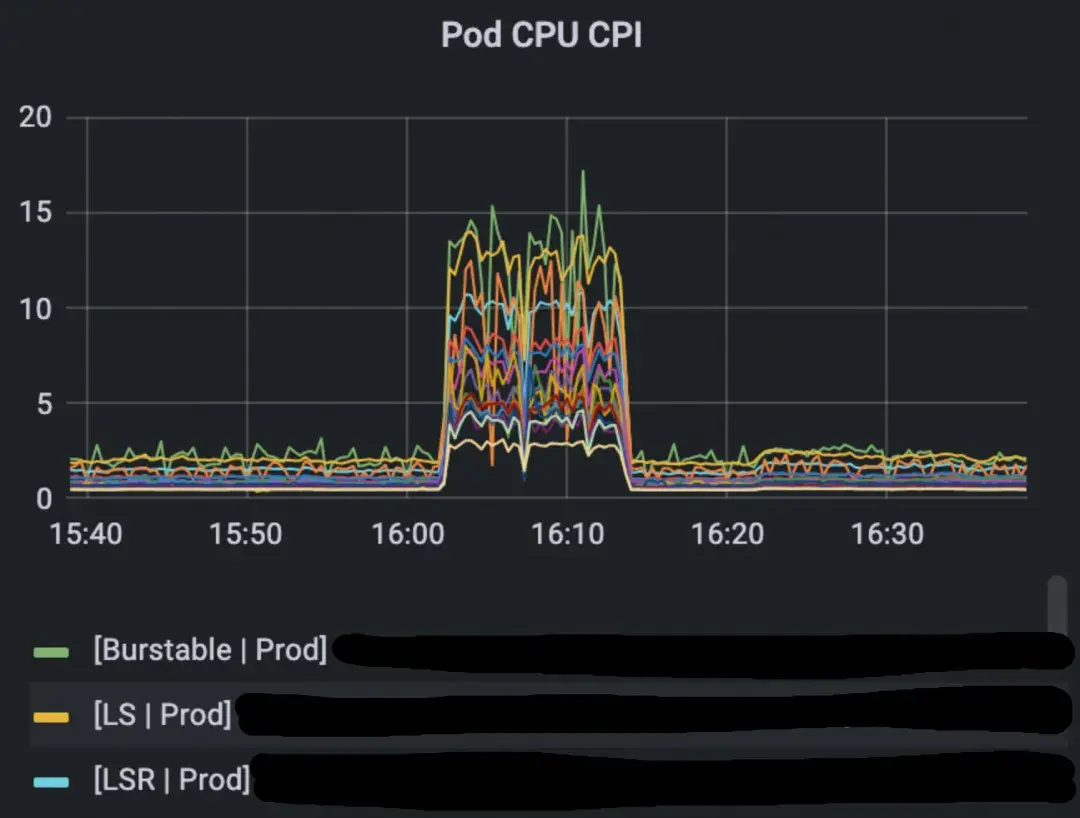
* 所有CPU物理核的CPI均突增,确认问题影响到了每一个计算核心。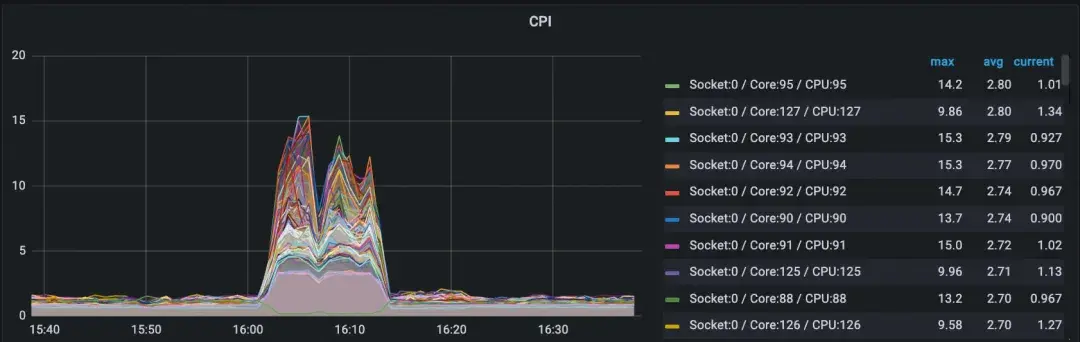
这些现象共同指向一个结论:问题根源可能在于某种系统性、硬件层面的竞争或阻塞,而非某个具体软件模块的缺陷。
三、问题定位:从微架构指标到“死马当活马医”
3.1 微架构指标分析与TopDown方法
为了深入硬件底层,我们在故障机器上采集了AMD CPU的性能监控单元(PMU) 微架构指标。
* 坏案例(Bad Case)现场数据: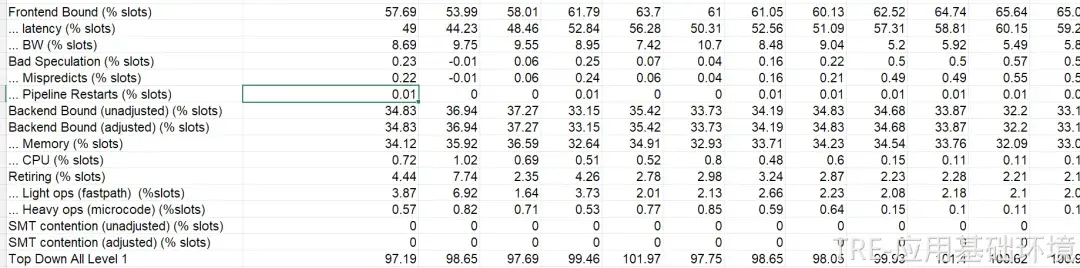



* 好案例(Good Case)基准数据: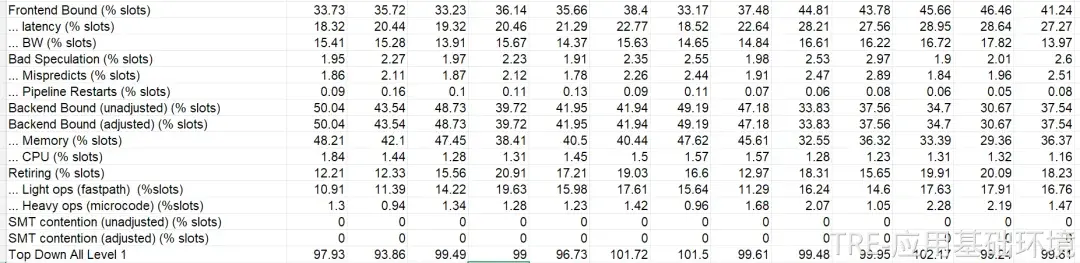



采用TopDown性能分析方法对数据进行剖析,得出了关键结论:
前端取指(Frontend Fetch)环节出现极端异常。具体表现为L1指令缓存缺失率(L1 I-cache Miss)极高,且大量的指令缓存行(Cache Line)来源于远程的CCD(Core Complex Die,AMD的多芯片模块设计)。这导致指令派发(Dispatch)通道被严重阻塞,进而使得整个核心的执行流水线变慢,对L3缓存和内存的访问也因此大幅下降。
3.2 初步猜想与暴力排查
基于以上分析,我们首先怀疑是某些业务Bug导致的Split Lock(分裂锁)问题,进而引发了Bus Lock(总线锁),从而阻塞了所有核心对总线的访问。然而,使用perf stat -e ls_locks.bus_lock命令并未抓取到预期的Bus Lock事件。
另一个猜想是,虚拟机内运行了代码跳转极大的业务(如JIT编译),导致L1指令缓存频繁失效。但在排查未果后,我们采取了一种看似“粗暴”但直接的方法:在故障发生时,向运行离线任务的Kata虚拟机(rund)发送SIGSTOP信号将其暂停。结果立竿见影——整机性能瞬间恢复正常。
这一结果将问题范围精确锁定在rund虚拟机内的某个进程。随后,我们通过串口登录虚拟机,对高CPU利用率的进程逐一发送SIGSTOP,最终成功定位到引发故障的特定业务进程。
3.3 业务特征归纳
通过采集多个故障现场并解析对应的ODPS项目和SQL表,我们发现出问题的业务具有共同特征:
* 它们使用C++编写的SQL执行引擎。
* 但在C++代码中,会直接调用Python函数(即ODPS的UDF - 用户定义函数) 来处理字符串等操作。
由此,我们形成了初步假设:问题很可能与Python UDF的执行机制有关。
四、问题确认:锁定Split Lock并成功复现
4.1 现场深度信息采集
对问题进程进行深入分析:
* top命令显示其某线程CPU利用率为100%。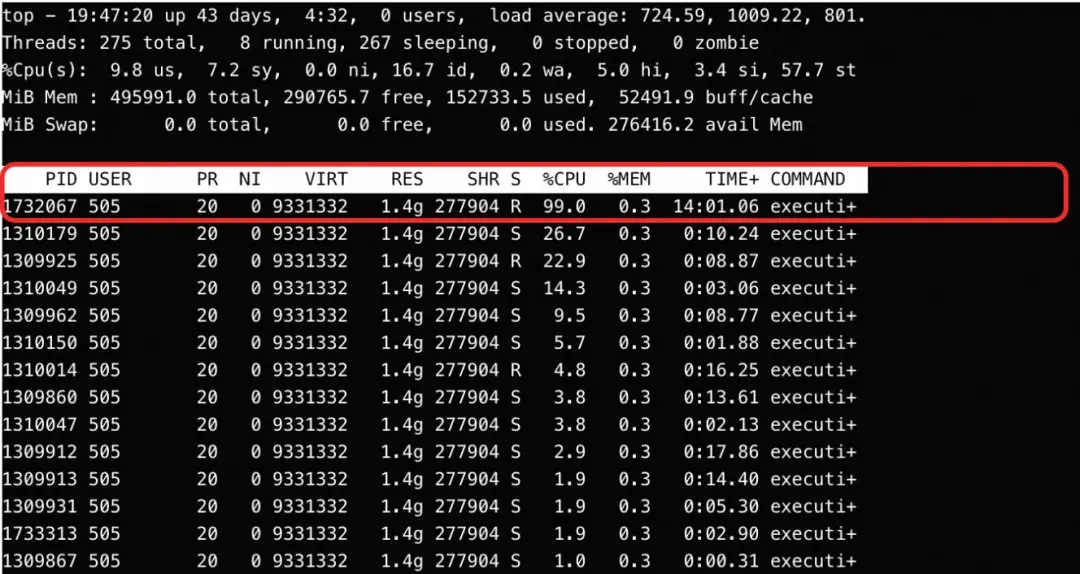
* 对该线程进行perf采样,发现时间几乎全消耗在__lll_lock_wait_private -> __x86_sys_futex的调用链中。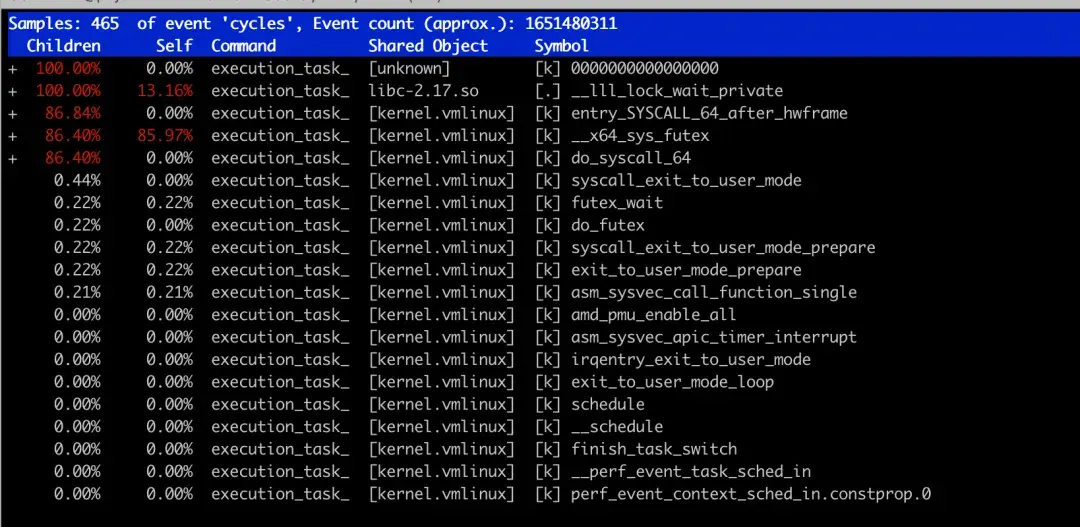
* 使用pstack获取该线程的堆栈,发现其正卡在__lll_lock_wait_private函数中。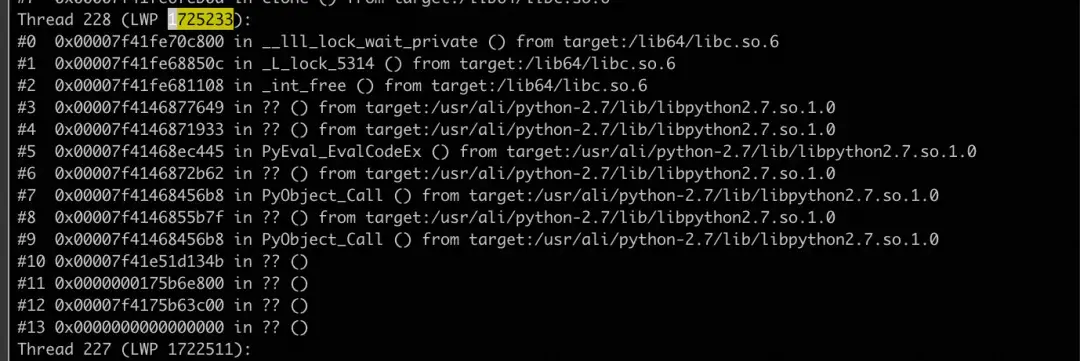
进一步分析__lll_lock_wait_private的汇编与伪C代码,发现其本质是一个自旋锁等待函数,最终会通过futex系统调用使线程休眠等待锁释放。
.globl __lll_lock_wait_private .type __lll_lock_wait_private,@function .hidden __lll_lock_wait_private .align 16 __lll_lock_wait_private: cfi_startproc pushq %r10 cfi_adjust_cfa_offset(8) pushq %rdx cfi_adjust_cfa_offset(8) cfi_offset(%r10, -16) cfi_offset(%rdx, -24) xorq %r10, %r10 /* No timeout. */ movl $2, %edx LOAD_PRIVATE_FUTEX_WAIT(%esi) cmpl %edx, %eax /* NB: %edx == 2 */ jne 2f 1: LIBC_PROBE(lll_lock_wait_private, 1, %rdi) movl $SYS_futex, %eax syscall 2: movl %edx, %eax xchgl %eax, (%rdi) /* NB: lock is implied */ testl %eax, %eax jnz 1b popq %rdx cfi_adjust_cfa_offset(-8) cfi_restore(%rdx) popq %r10 cfi_adjust_cfa_offset(-8) cfi_restore(%r10) retq cfi_endproc .size __lll_lock_wait_private,.-__lll_lock_wait_private
void __lll_lock_wait_private(int *lock, int val)
{
int expected = 2; /* Contended state value */
/* If the current value is not 2 (contended), skip the initial wait */
if (val == expected) {
/* Wait on the futex until the lock value changes */
syscall(SYS_futex,
lock, /* futex address */
FUTEX_WAIT | FUTEX_PRIVATE_FLAG, /* operation */
expected, /* expected value */
NULL, /* timeout (no timeout) */
NULL, /* uaddr2 (unused) */
0); /* val3 (unused) */
}
/* Try to acquire the lock atomically */
while (__sync_val_compare_and_swap(lock, 0, expected) != 0) {
/* Lock is still contended, wait again */
syscall(SYS_futex,
lock, /* futex address */
FUTEX_WAIT | FUTEX_PRIVATE_FLAG, /* operation */
expected, /* expected value */
NULL, /* timeout (no timeout) */
NULL, /* uaddr2 (unused) */
0); /* val3 (unused) */
}
/* Lock acquired successfully */
}关键发现:使用bpftrace抓取该进程futex系统调用的参数,发现其等待的锁地址(uaddr)是0xffffffff。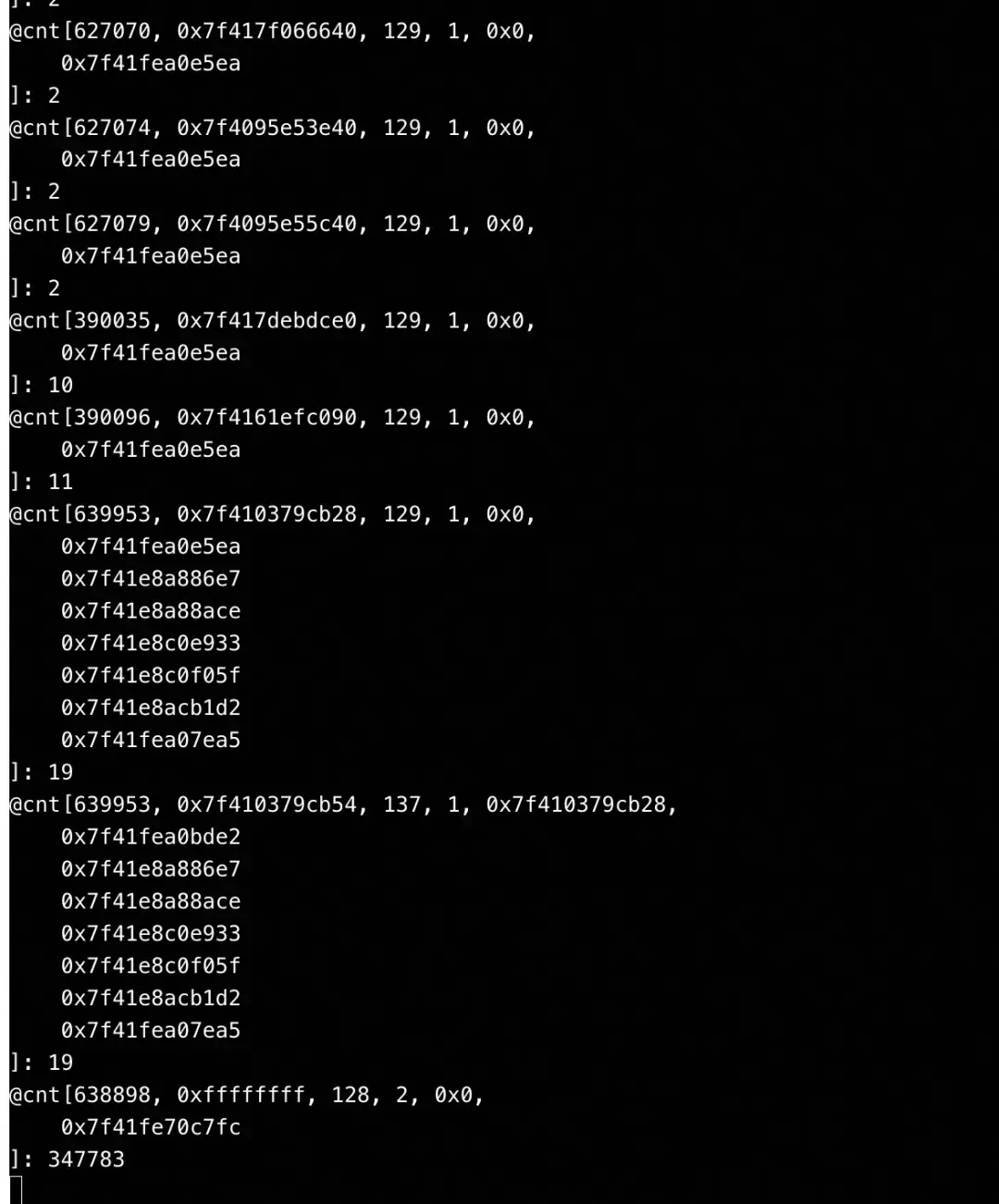
这个异常的地址(通常是一个无效的地址或特殊值)高度指向了 split lock 问题。随后,在虚拟机内使用perf stat -e ls_locks.bus_lock命令,成功抓取到了bus_lock事件,并确认其正是由问题线程引发。
4.2 构造测试,成功复现并发现平台差异
为了验证猜想,我们编写了一个简单的测试程序:分配一块内存,通过地址偏移使其跨越两个缓存行(Cache Line),然后对这个跨界的地址进行原子锁操作(模拟split lock)。
// 简化示例:制造一个跨缓存行的地址并进行原子操作 void* addr = malloc(64); void* split_addr = (char*)addr + 63; // 使地址横跨第63和64字节边界 __lll_lock_wait_private(split_addr, 0);
测试结果具有重大发现:
* 在AMD机器上:运行此测试程序后,整机所有核心的CPI都异常升高,再现了生产故障现象。
* 在Intel机器上:仅运行该程序的物理核及其超线程核的CPI升高,其他核心不受影响。
对比测试数据:
AMD机器(影响全局)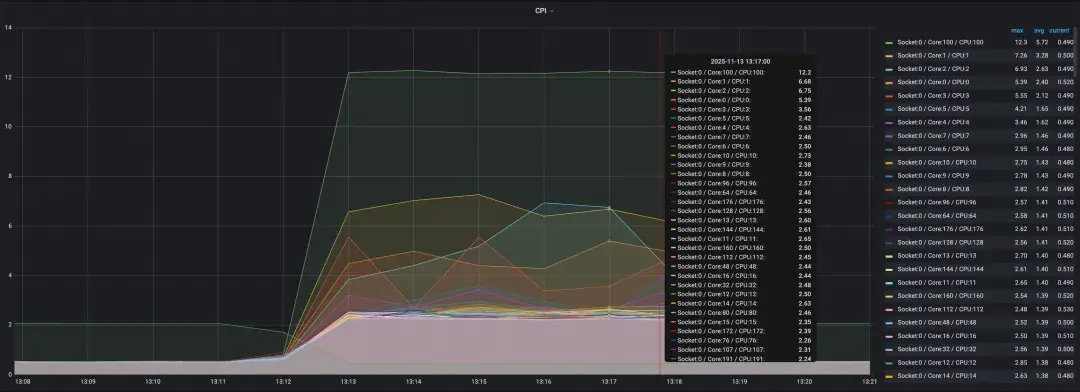
Intel机器(影响局部)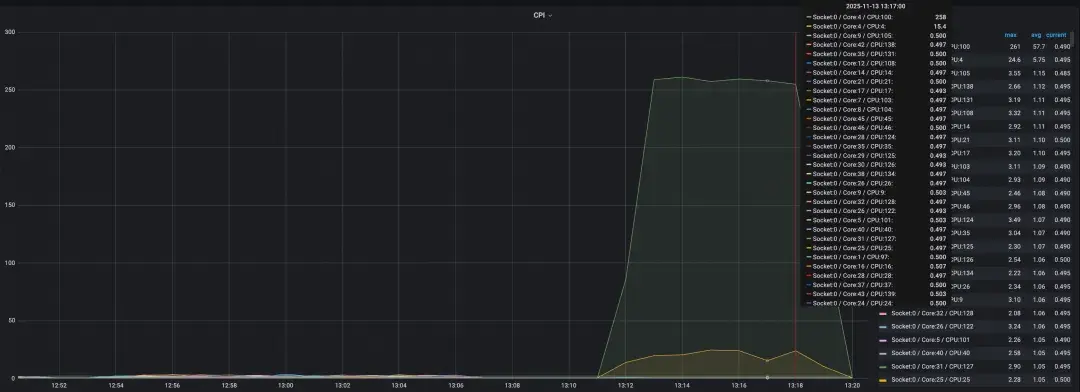
/* Extracted __lll_lock_wait_private function from glibc
* This is a low-level lock wait function for futex-based locking
*/
.text
.globl lll_lock_wait_private_extracted
.type lll_lock_wait_private_extracted,@function
.align 16
lll_lock_wait_private_extracted:
/* Function prologue - save registers */
pushq %r10
pushq %rdx
/* Setup futex parameters */
xorq %r10, %r10 /* No timeout (NULL) */
movl $2, %edx /* Expected value = 2 (contended) */
movl $128, %esi /* futex operation: FUTEX_WAIT | FUTEX_PRIVATE_FLAG = 0 | 128 = 128 */
/* Check if lock is already contended */
cmpl %edx, %eax /* Compare current value with 2 */
jne 2f /* If not 2, try to acquire lock */
1: /* Wait loop - call futex syscall */
movl $202, %eax /* futex system call number (__NR_futex = 202 on x86_64) */
syscall /* Call kernel */
2: /* Try to acquire lock atomically */
movl %edx, %eax /* Load value 2 into %eax */
xchg %eax, (%rdi) /* Atomic exchange with lock */
/* Check if we got the lock */
testl %eax, %eax /* Test if previous value was 0 */
jnz 1b /* If not, go back to waiting */
/* Function epilogue - restore registers and return */
popq %rdx
popq %r10
retq
.size lll_lock_wait_private_extracted,.-lll_lock_wait_private_extracted
#define _GNU_SOURCE
#include<stdio.h>
#include<stdlib.h>
#include<pthread.h>
#include<unistd.h>
#include<sys/syscall.h>
#include<linux/futex.h>
#include<errno.h>
#include<string.h>
#include<time.h>
/* Declaration of our extracted assembly function */
externvoidlll_lock_wait_private_extracted(int *lock);
intmain(){
printf("Testing extracted __lll_lock_wait_private function\n");
printf("================================================\n");
longlong a=malloc(sizeof(longlong) * 8);
int *x = a+15;
printf("%lx %lx\n", a, x);
*x = 2;
lll_lock_wait_private_extracted(x);
printf("\n=== All Tests Completed ===\n");
return0;
}4.3 什么是Split Lock?
Split Lock是指对跨越两个缓存行(通常为64字节边界)的单一变量进行的原子读写操作(如LOCK前缀的指令)。由于现代CPU的原子操作通常以缓存行为单位,处理Split Lock需要锁定整个内存总线(Bus Lock),这会序列化所有核心的内存访问,导致系统性能断崖式下跌。
专家解释:Intel很早就意识到此问题,并在微架构层面进行了优化(例如,将影响局部化)。而AMD的某些代际CPU在此方面的防护机制可能有所不同,导致Split Lock更容易引发全局性的Bus Lock。
五、深度根因分析:内存分配器混用之殇
问题进程为何会持有一个地址为0xffffffff的锁?我们对问题进程进行了gcore生成内存转储,并通过gdb(需进入正确的mount namespace并安装debuginfo)解析,得到了崩溃时的完整堆栈。堆栈显示,问题发生在Python解释器中调用__libc_free释放内存时。
5.1 深入Glibc代码迷宫
追踪__libc_free -> _int_free的代码路径,发现触发_L_lock_5314(即__lll_lock_wait_private)的锁,是av->mutex。而这里的av指针,正是0xffffffff。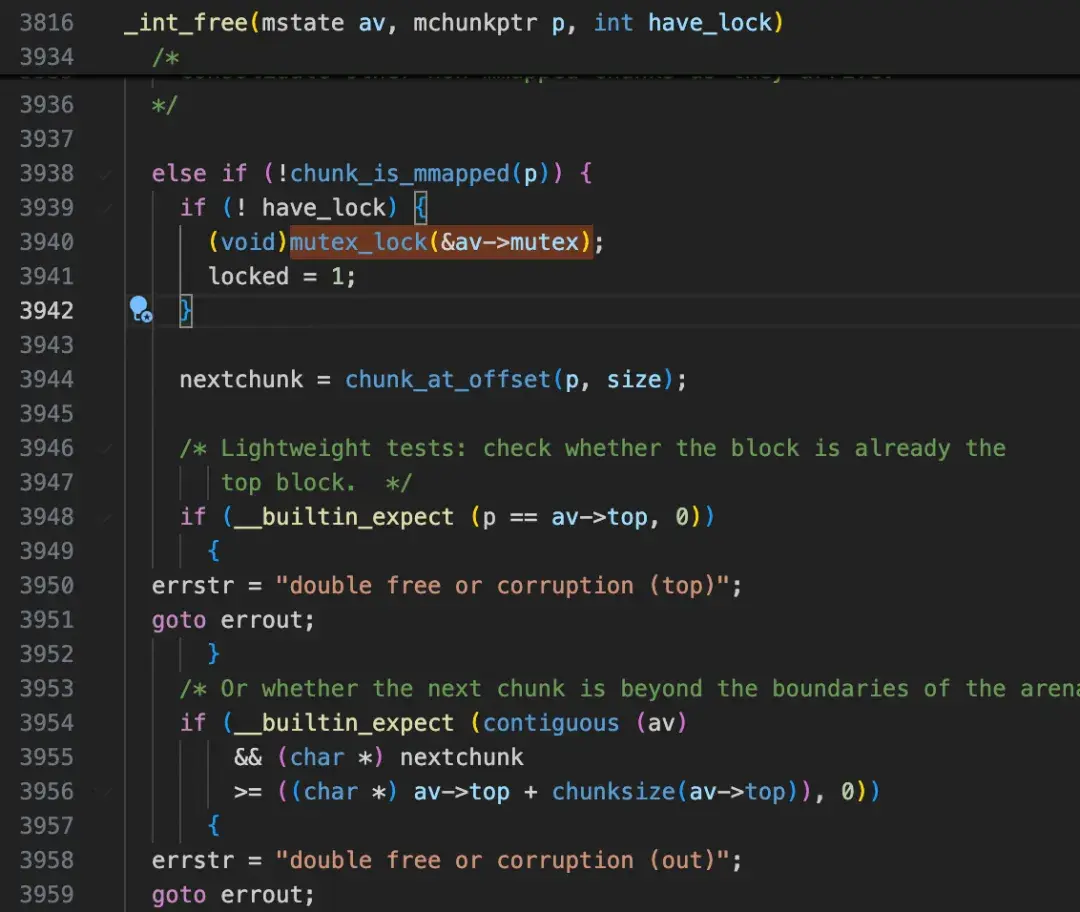
#define mutex_lock(m) __libc_lock_lock (*(m))
# ifndef __libc_lock_lock
# define __libc_lock_lock(NAME) \
({ lll_lock (NAME, LLL_PRIVATE); 0; })
# endif
#define lll_lock(futex, private) \
(void) \
({ int ignore1, ignore2, ignore3; \
if (__builtin_constant_p (private) && (private) == LLL_PRIVATE) \
__asm __volatile (__lll_lock_asm_start \
".subsection 1\n\t" \
".type _L_lock_%=, @function\n" \
"_L_lock_%=:\n" \
"1:\tlea %2, %%" RDI_LP "\n" \
"2:\tsub $128, %%" RSP_LP "\n" \
"3:\tcallq __lll_lock_wait_private\n" \
"4:\tadd $128, %%" RSP_LP "\n" \
"5:\tjmp 24f\n" \
"6:\t.size _L_lock_%=, 6b-1b\n\t" \
".previous\n" \
LLL_STUB_UNWIND_INFO_5 \
"24:" \
: "=S" (ignore1), "=&D" (ignore2), "=m" (futex), \
"=a" (ignore3) \
: "0" (1), "m" (futex), "3" (0) \
: "cx", "r11", "cc", "memory"); \
else \
__asm __volatile (__lll_lock_asm_start \
".subsection 1\n\t" \
".type _L_lock_%=, @function\n" \
"_L_lock_%=:\n" \
"1:\tlea %2, %%" RDI_LP "\n" \
"2:\tsub $128, %%" RSP_LP "\n" \
"3:\tcallq __lll_lock_wait\n" \
"4:\tadd $128, %%" RSP_LP "\n" \
"5:\tjmp 24f\n" \
"6:\t.size _L_lock_%=, 6b-1b\n\t" \
".previous\n" \
LLL_STUB_UNWIND_INFO_5 \
"24:" \
: "=S" (ignore1), "=D" (ignore2), "=m" (futex), \
"=a" (ignore3) \
: "1" (1), "m" (futex), "3" (0), "0" (private) \
: "cx", "r11", "cc", "memory"); \
}) av是mstate(malloc状态)结构体指针,其第一个字段就是mutex。因此av->mutex的地址就等于av自身。问题转化为:为何会传入一个错误的av指针?
typedefstructmalloc_state *mstate;
structmalloc_state {
/* Serialize access. */
mutex_t mutex;
/* Flags (formerly in max_fast). */
int flags;
/* Fastbins */
mfastbinptr fastbinsY[NFASTBINS];
/* Base of the topmost chunk -- not otherwise kept in a bin */
mchunkptr top;
/* The remainder from the most recent split of a small request */
mchunkptr last_remainder;
/* Normal bins packed as described above */
mchunkptr bins[NBINS * 2 - 2];
/* Bitmap of bins */
unsignedint binmap[BINMAPSIZE];
/* Linked list */
structmalloc_state *next;
/* Linked list for free arenas. Access to this field is serialized
by free_list_lock in arena.c. */
structmalloc_state *next_free;
/* Number of threads attached to this arena. 0 if the arena is on
the free list. Access to this field is serialized by
free_list_lock in arena.c. */
INTERNAL_SIZE_T attached_threads;
/* Memory allocated from the system in this arena. */
INTERNAL_SIZE_T system_mem;
INTERNAL_SIZE_T max_system_mem;
};代码回溯显示,av是通过arena_for_chunk(p)计算得来的,而p = mem2chunk(mem)(mem是要释放的内存地址减去0x10)。对于问题内存块,其size字段的某个标志位被置位,导致它被判定为非主分配区(main_arena) 分配的内存,从而走入heap_for_ptr(ptr)->ar_ptr这个分支。
strong_alias (__libc_free, __free) strong_alias (__libc_free, free)
void
__libc_free(void* mem)
{
mstate ar_ptr;
mchunkptr p; /* chunk corresponding to mem */
void (*hook) (__malloc_ptr_t, const__malloc_ptr_t)
= force_reg (__free_hook);
if (__builtin_expect (hook != NULL, 0)) {
(*hook)(mem, RETURN_ADDRESS (0));
return;
}
if (mem == 0) /* free(0) has no effect */
return;
p = mem2chunk(mem);
if (chunk_is_mmapped(p)) /* release mmapped memory. */
{
/* see if the dynamic brk/mmap threshold needs adjusting */
if (!mp_.no_dyn_threshold
&& p->size > mp_.mmap_threshold
&& p->size <= DEFAULT_MMAP_THRESHOLD_MAX)
{
mp_.mmap_threshold = chunksize (p);
mp_.trim_threshold = 2 * mp_.mmap_threshold;
LIBC_PROBE (memory_mallopt_free_dyn_thresholds, 2,
mp_.mmap_threshold, mp_.trim_threshold);
}
munmap_chunk(p);
return;
}
ar_ptr = arena_for_chunk(p);
_int_free(ar_ptr, p, 0);
}
libc_hidden_def (__libc_free)#define mem2chunk(mem) ((mchunkptr)((char*)(mem) - 2*SIZE_SZ))
typedefstructmalloc_chunk* mchunkptr;
structmalloc_chunk {
INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */
structmalloc_chunk* fd; /* double links -- used only if free. */
structmalloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
structmalloc_chunk* fd_nextsize;/* double links -- used only if free. */
structmalloc_chunk* bk_nextsize;
};#define arena_for_chunk(ptr) \ (chunk_non_main_arena(ptr) ? heap_for_ptr(ptr)->ar_ptr : &main_arena) #define chunk_non_main_arena(p) ((p)->size & NON_MAIN_ARENA) #define NON_MAIN_ARENA 0x4
真相浮现:heap_for_ptr(ptr)的计算方式是ptr & ~(HEAP_MAX_SIZE-1)。对于我们的问题指针,这个计算意外地得到了0xffffffff,从而导致后续一切错误。
define DEFAULT_MMAP_THRESHOLD_MAX(4 * 1024 * 1024 * sizeof(long)) define HEAP_MAX_SIZE(2 * DEFAULT_MMAP_THRESHOLD_MAX) #define heap_for_ptr(ptr) \ ((heap_info *)((unsigned long)(ptr) & ~(HEAP_MAX_SIZE-1)))

至此,有两种可能:
1. heap_info结构体在内存中被踩踏(内存越界写入),导致ar_ptr字段损坏。
2. 要释放的内存块头部(malloc_chunk)被踩踏,导致其size标志位被错误设置,走入错误分支。
5.2 Python对象内存分析
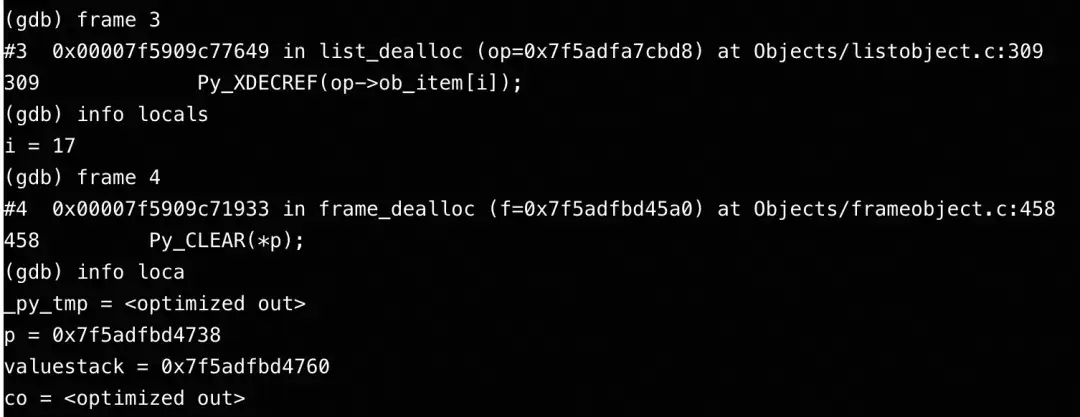
分析Python堆栈,发现是在释放一个PyListObject列表中的第17个元素(一个字符串对象)时出错。
staticvoid
list_dealloc(PyListObject *op)
{
Py_ssize_t i;
PyObject_GC_UnTrack(op);
Py_TRASHCAN_SAFE_BEGIN(op)
if (op->ob_item != NULL) {
/* Do it backwards, for Christian Tismer.
There's a simple test case where somehow this reduces
thrashing when a *very* large list is created and
immediately deleted. */
i = Py_SIZE(op);
while (--i >= 0) {
Py_XDECREF(op->ob_item[i]); //这一行
}
PyMem_FREE(op->ob_item);
}
if (numfree < PyList_MAXFREELIST && PyList_CheckExact(op))
free_list[numfree++] = op;
else
Py_TYPE(op)->tp_free((PyObject *)op);
Py_TRASHCAN_SAFE_END(op)
}
typedefstruct {
PyObject_VAR_HEAD
/* Vector of pointers to list elements. list[0] is ob_item[0], etc. */
PyObject **ob_item;
/* ob_item contains space for 'allocated' elements. The number
* currently in use is ob_size.
* Invariants:
* 0 <= ob_size <= allocated
* len(list) == ob_size
* ob_item == NULL implies ob_size == allocated == 0
* list.sort() temporarily sets allocated to -1 to detect mutations.
*
* Items must normally not be NULL, except during construction when
* the list is not yet visible outside the function that builds it.
*/
Py_ssize_t allocated;
} PyListObject;解析该列表和字符串对象,发现它们本身内容看起来是正常的。字符串对象由malloc分配,应由free释放,逻辑上不应有问题。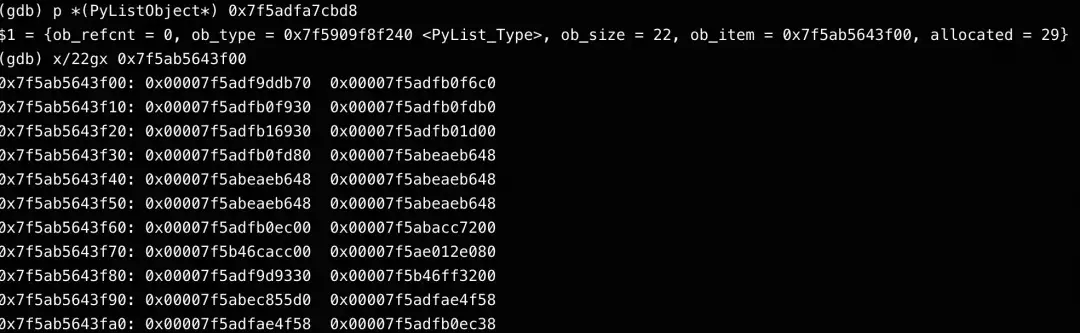

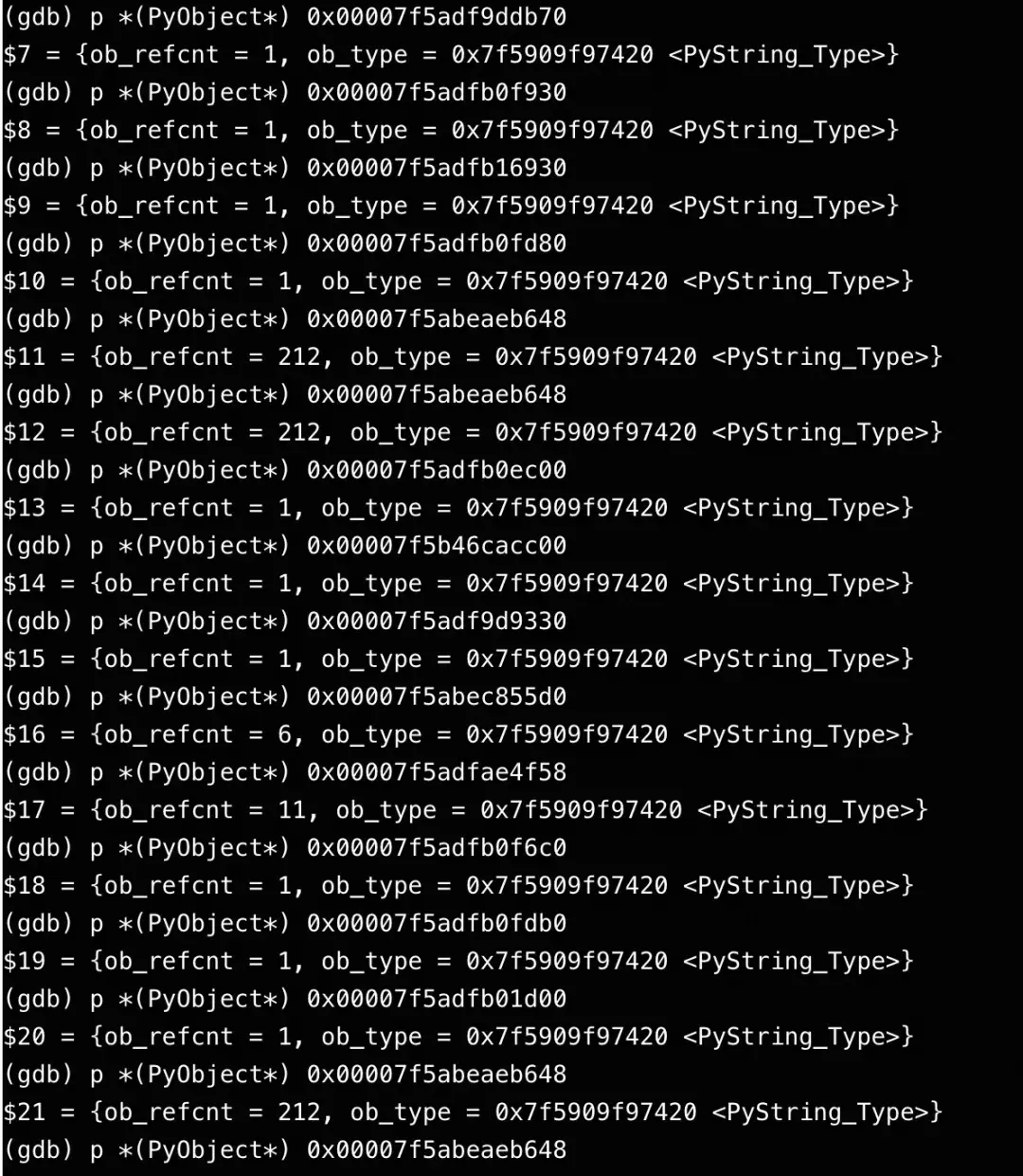
5.3 矛盾与转折:发现jemalloc
深入分析问题内存块及其周边的内存布局时,发现了一些不寻常的规律性结构,不像典型的glibc ptmalloc分配模式。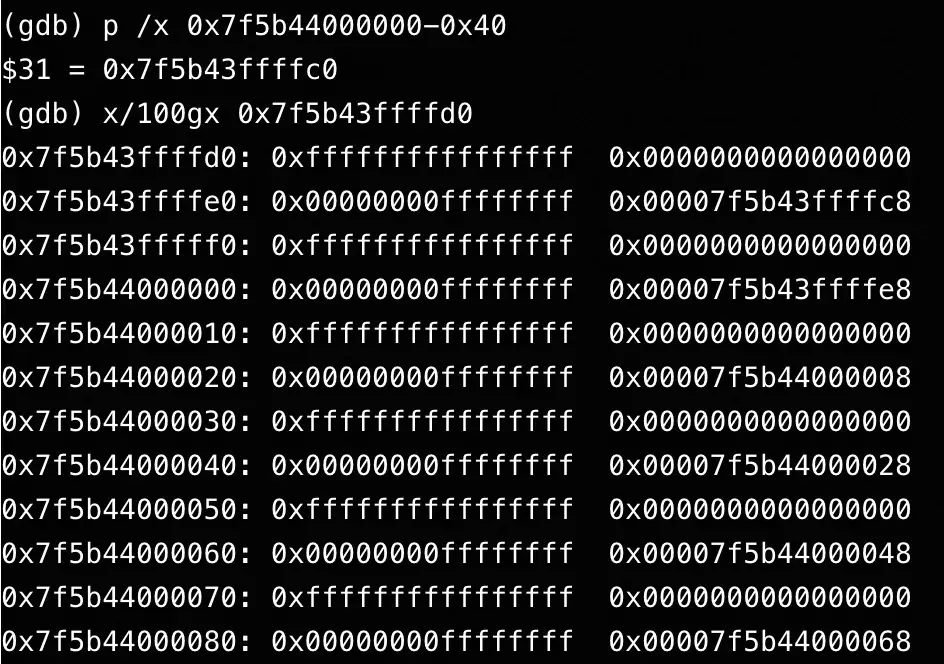

关键线索:检查问题进程加载的动态库,发现其链接了jemalloc!这意味着该C++业务程序使用jemalloc作为其内存分配器。而Python解释器作为系统库,通常使用glibc的ptmalloc。
混合分配器的复杂局面出现了:
* 猜想1:C++/jemalloc 与 Python/ptmalloc 各自管理自己的内存,互不干扰。(可能性低,否则问题会更普遍)
* 猜想2:业务使用jemalloc申请内存,但错误地用libc的free去释放。(可能性高,这会导致未定义行为)
* 猜想3:存在某种机制(如__free_hook)在正常时能正确路由,但在特定条件下失效。
5.4 Hook机制失效与fork的“致命巧合”
glibc提供了__malloc_hook和__free_hook机制,允许像jemalloc这样的替换分配器进行拦截。正常情况下,jemalloc会设置这些hook指向自己的函数。检查发现,__free_hook确实已被设置为je_free。
然而,我们的故障现场却走到了libc的_int_free,说明__free_hook在那一刻没有生效。查阅glibc源码发现,在fork调用时,如果__malloc_initialized >= 1,__free_hook会被临时修改为free_atfork。
而__malloc_initialized变为1,只需进程调用过malloc, malloc_trim等glibc内存管理函数即可。eBPF追踪证实,业务进程确实会调用fork。
5.5 完整的故障传导路径推演
结合所有线索,我们重构了故障发生的完美风暴:
环境设定:ODPS作业通过dlopen加载libpython.so时使用了RTLD_DEEPBIND标志,导致Python解释器内的malloc/free符号绑定到glibc而非jemalloc。
Hook路由:jemalloc通过设置__free_hook,使得来自Python的free调用能正确路由到je_free。
初始化触发:业务代码(可能无意中)调用了malloc_trim等函数,导致glibc的ptmalloc初始化,__malloc_initialized被设为1。
竞争条件:在某个时刻,作业进程调用了fork。在fork的处理过程中,__free_hook被临时替换为glibc内部的free_atfork。
致命一击:几乎同时,Python解释器的一个线程试图释放一个字符串对象。此时__free_hook指向free_atfork,但该内存块实际上是由jemalloc分配的。free_atfork无法识别jemalloc的内存结构,按照glibc的规则进行解析,错误地计算出了av = 0xffffffff。
Split Lock引爆:在对这个错误地址进行锁操作时,由于其特殊性(可能恰好跨缓存行),触发了Split Lock,在AMD平台上升级为全局Bus Lock,最终导致整机CPI飙升。
这是一个极其隐蔽的内存分配器混用 + 特定时序竞争条件引发的底层硬件故障。
六、延伸思考与行业洞察
6.1 为何宿主机感知迟钝?
- PMU隔离:宿主机的性能监控单元(PMU)上下文与虚拟机是隔离的,因此宿主机perf工具无法直接捕获虚拟机内部产生的bus_lock事件。
- 内核日志差异:
- 在Intel平台上,发生split lock时,宿主机内核会打印明确的AC(Alignment Check)异常日志(如#AC: ... took a split_lock trap)。
- 在AMD平台上,由于当时所用内核版本(5.10)尚未合入对AMD的split lock检测补丁,宿主机缺乏有效的日志告警机制。
6.2 深究“WHY AMD?”——硬件微架构差异
Split Lock导致性能问题并非新事,但Intel和AMD的处理策略存在差异:
* Intel:早在多年前就已意识到此问题,并在微架构层面进行了硬件优化(具体技术属于商业机密)。其优化目标是将Split Lock的影响尽可能限制在发生该操作的单个物理核内,避免全局性的Bus Lock。此外,通过内核参数split_lock_detect的ratelimit选项,能进一步减轻影响。
* AMD:在当时的架构(如Zen 3/Zen 4)中,对Split Lock的处理可能更接近于理论上的“总线锁”行为,一旦发生,容易广播到整个CPU乃至套接字(Socket),导致全局性性能塌方。这反映了新兴服务器CPU厂商在生态成熟过程中需要逐步填补的经验坑。
未来趋势:随着AMD EPYC在数据中心市场份额扩大,其与OS、虚拟化层的协同优化会加速。AMD已承诺在下一代CPU微架构中采取措施缓解此问题,内核补丁也在积极跟进。
6.3 如何从代码层面规避Split Lock?(开发者指南)
对于C/C++等底层语言开发者,遵循以下最佳实践可有效避免无意中引入Split Lock:
1. 确保原子变量对齐:使用编译器属性或对齐分配,确保原子变量地址对齐到其自然边界(如8字节对齐的变量地址末3位为0)。
// 推荐:64 字节对齐,避免跨行和伪共享 alignas(64) atomic<uint64_t> counter; // 针对 128 位原子类型,16 字节对齐 alignas(16) atomic<__int128> big_counter;
2. 优化结构体布局:避免将大型原子变量放在结构体中间,防止因结构体打包(padding)导致其错位。
// 不推荐:原子变量可能因前面的成员而发生位移,导致跨行
structBadExample {
char a; // 占用 1 字节
atomic<__int128> val; // 可能跨缓存行
};
// 推荐:将对齐要求最高的成员放在最前,并显式声明
structGoodExample {
alignas(16) atomic<__int128> val;
char a;
};
3. 拆分大型原子操作:对于非必需的128位原子操作,考虑用两个独立的64位原子操作替代。
structPaddedCounter {
alignas(64) atomic<uint64_t> low;
alignas(64) atomic<uint64_t> high;
};
4. 警惕未对齐指针:绝对不要对未明确对齐的指针进行原子操作。
//错误:malloc 不保证 16 字节对齐(尤其老 libc) void* ptr = malloc(sizeof(atomic<__int128>)); atomic<__int128>* p = new(ptr) atomic<__int128>; //正确: 使用 aligned_alloc void* aligned_ptr = aligned_alloc(16, sizeof(atomic<__int128>)); atomic<__int128>* p = new(aligned_ptr) atomic<__int128>;
5. 编译时检查:使用static_assert确保原子变量的对齐符合预期。
static_assert(alignof(atomic<__int128>) >= 16, "128-bit atomic must be 16-byte aligned");
6. 慎用packed结构体:在编译器packed属性修饰的结构体中避免使用原子类型。
#pragma pack(push, 1)
structPacked {
uint8_t flag;
atomic<uint64_t> counter; // 错误:8字节也可能因紧凑布局跨行
};
#pragma pack(pop)6.4 Split Lock检测手段
- Intel:可通过perf stat -e r102c(或cpu/split_lock/事件)监控,并查看内核dmesg日志。
- AMD:使用perf stat -e ls_locks.bus_lock监控。内核的split_lock_detect功能支持需要等待新版本内核。
七、解决方案与后续措施
7.1 业务侧(ODPS)根治方案
- 短期缓解:对频繁触发问题的作业,启用 isolation模式,强制业务进程全局使用tcmalloc,彻底避免jemalloc与glibc ptmalloc的混用风险。经过半个月灰度,该方案基本杜绝了问题复现。
- 长期根除:修改代码,避免调用malloc_trim等会触发glibc ptmalloc初始化的函数,从根本上防止__free_hook在fork时被篡改。同时评估RTLD_DEEPBIND的使用必要性。
7.2 平台与内核侧加固
- 内核支持:积极验证并推动 AMD Split Lock检测内核补丁 的合入。这将使AMD服务器能像Intel一样,在内核日志中报告Split Lock事件,提供关键排障线索。
- 监控预警:在监控系统中增加对ls_locks.bus_lock性能事件的常态化采集与阈值告警,做到主动发现。
7.3 与硬件厂商协同
- 与AMD保持技术沟通,推动其在未来CPU微架构中优化Split Lock的处理逻辑,降低其对系统全局性能的冲击。
本文由主机测评网发布,不代表主机测评网立场,转载联系作者并注明出处:https:///yunwei/9680.html
