
CDN是什么?内容分发网络工作原理、核心优势与应用场景详解
1. 引言:互联网的瓶颈与 CDN 的诞生
自 20 世纪 90 年代以来,万维网(World Wide Web)的普及彻底改变了人们获取信息的方式。早期网站内容简单,用户量少,一台位于数据中心的源服务器(Origin Server)足以应对全球的访问请求。然而,随着互联网的爆炸式增长,特别是高清视频、社交媒体、在线游戏和电子商务的兴起,这种传统的“中心化”架构开始暴露出严重的问题:
- 高延迟:如果一个位于美国的用户访问一台部署在德国的服务器,数据包需要跨越半个地球,经历数千公里的传输,产生数百毫秒的延迟。这对于实时交互应用(如视频会议、在线游戏)是致命的。
- 网络拥塞:所有流量都涌向同一个源站,导致源站所在的数据中心出口带宽成为瓶颈,尤其在流量高峰时段,网络拥堵导致丢包和重传,进一步恶化用户体验。
- 单点故障(SPOF):源服务器一旦出现硬件故障、软件崩溃或遭受 DDoS 攻击,整个网站将完全瘫痪。
- 高昂的带宽成本:为了应对峰值流量,源站必须准备充足的带宽资源,而这些资源在大部分时间处于闲置状态,造成巨大浪费。
为了解决上述挑战,内容分发网络(Content Delivery Network,简称 CDN)应运而生。其核心理念非常简单且巧妙:将内容复制并缓存到离用户更近的地方。
专家建议:对于初创企业或中小型网站,CDN 不再是“可选项”,而是“必选项”。它不仅能提升用户体验(UX),还能显著降低源服务器的计算和带宽压力,是保障业务连续性的第一道防线。
CDN 并不是一个单一的技术,而是一整套分布式系统架构的统称。它通过在遍布全球的多个地理位置部署边缘服务器(Edge Server),形成一个覆盖网络。当用户请求内容时,CDN 的智能调度系统会将请求导向最优的边缘节点(通常是与用户网络距离最近、负载最轻、响应最快的节点),由该节点直接响应用户。如果该节点没有缓存所需内容,它会向源站请求并缓存后再返回给用户。
简单来说,CDN 就像互联网世界的“分布式仓储系统”。源站是“中央工厂”,而遍布各地的 CDN 节点就是“区域仓库”。用户购物时,商品从最近的区域仓库发货,而不是每次都从中央工厂长途运输,从而大幅缩短了等待时间。
2. CDN 的核心思想与基本原理
要深入理解 CDN,首先需要掌握其核心的设计思想和基本工作原理。
2.1 核心思想:分布、缓存、智能调度
CDN 的核心思想可以概括为三个关键词:
- 分布:CDN 服务商在全球范围内部署大量的边缘节点(Point of Presence,PoP),每个 PoP 通常由成百上千台服务器组成。这些节点覆盖了不同的地理区域和网络运营商(ISP,如中国电信、中国联通、AT&T 等)。分布的密度和广度直接决定了 CDN 的服务质量。
- 缓存:CDN 节点上运行着专用的缓存软件(如 Nginx、Apache Traffic Server、Squid 等)。它们会主动或被动地将源站的内容(如图片、视频、HTML 页面、API 响应)存储下来。缓存不是永久性的,而是遵循一定的策略(如 TTL)进行更新和淘汰。
- 智能调度:当用户发起请求时,CDN 必须能够准确判断哪个节点是“最优”的。这需要一个全局的负载均衡系统(Global Server Load Balancing,GSLB)。它综合考量用户的地理位置、网络状况、节点负载、响应时间等多种因素,动态地将用户引导至最合适的节点。
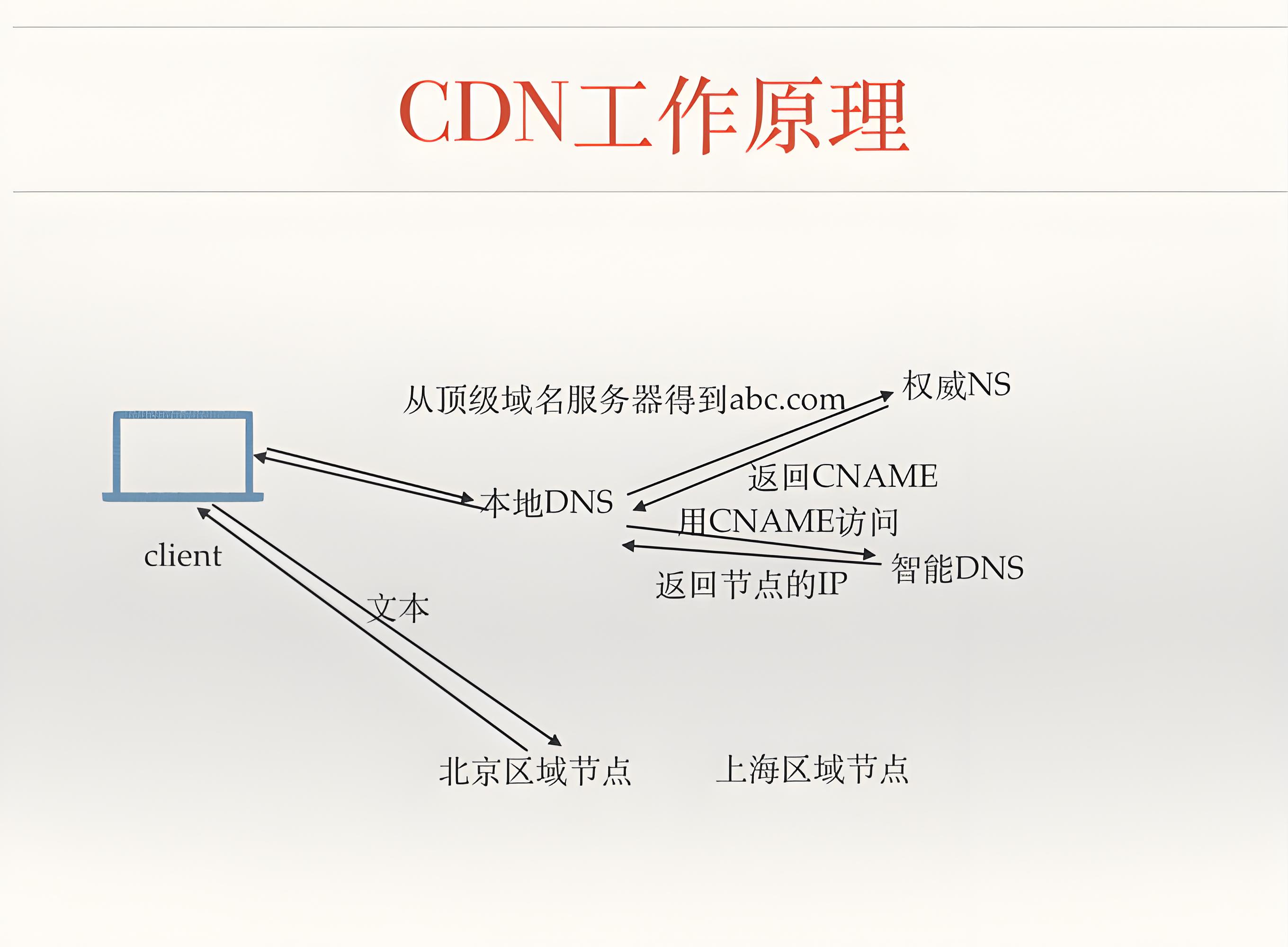
2.2 基本工作原理
下图(逻辑示意图)描述了 CDN 处理一次用户请求的完整生命周期:
[用户设备] --> (DNS 查询) --> [CDN 的权威 DNS 服务器] --> (返回最优边缘节点 IP) [用户设备] --> (HTTP 请求) --> [CDN 边缘节点] [CDN 边缘节点] --> (检查缓存) ├─ 如果命中缓存: --> (直接返回缓存内容) --> [用户设备] └─ 如果未命中: --> (回源请求) --> [源站服务器] --> (获取内容并缓存) --> [用户设备]
步骤详解:
- 用户发起请求:用户在浏览器中输入
http://www.example.com/image.jpg。 - DNS 解析与调度:用户的 Local DNS 服务器(通常由 ISP 提供)会递归查询
www.example.com的 IP 地址。如果该域名已接入 CDN 服务,则其权威 DNS 服务器(或 CDN 提供的智能 DNS 服务器)会接管解析。CDN 的 GSLB 系统会根据用户 Local DNS 的 IP 地址(大致推断用户的地理位置和运营商)、当前各边缘节点的负载、链路质量等,计算出“最优”的边缘节点 IP 地址,并将其返回给 Local DNS。 - 建立连接:Local DNS 将获得的 IP 返回给用户设备。用户设备向该 IP(即 CDN 边缘节点)发起 HTTP/HTTPS 请求。
- 边缘节点处理:
- 缓存命中(HIT):边缘节点收到请求后,首先根据请求的 URL、Host 头、参数等生成缓存键(Cache Key),并在本地存储中查找。如果找到未过期的内容,则直接将该内容组装成 HTTP 响应返回给用户。这个过程非常快,通常只需几毫秒。
- 缓存未命中(MISS):如果本地没有缓存,或者缓存已过期,边缘节点会向源站服务器发起“回源”请求。这个请求可能经过优化(如链路复用、协议转换),以最快速度从源站获取内容。
- 内容返回与缓存:源站返回内容给边缘节点。边缘节点一方面根据 HTTP 响应头中的缓存控制指令(如
Cache-Control: max-age=3600)决定是否缓存以及缓存多久,然后将内容存储到本地;另一方面,将内容转发给用户设备。 - 后续请求:之后,当有其他用户请求相同内容时,边缘节点就可以直接返回缓存内容,无需再次回源。
通过这套机制,CDN 实现了三大核心价值:降低用户访问延迟、减轻源站压力、提高整体可用性。
3. CDN 的关键技术组件
一个成熟的 CDN 系统由多个精密的组件协同工作。理解这些组件是掌握 CDN 技术原理的基础。
3.1 边缘节点(PoP - Point of Presence)
边缘节点是 CDN 的“最后一公里”,是直接面向用户并提供服务的服务器集群。
- 物理分布:一个 PoP 通常位于一个或多个互联网交换中心(IXP)或数据中心内部,具备高带宽、低延迟的网络接入。全球顶级的 CDN 服务商(如 Akamai、Cloudflare、AWS CloudFront)拥有数万个 PoP,覆盖全球各大洲。
- 硬件构成:每个 PoP 内部由成百上千台通用的 x86/ARM 服务器组成。这些服务器配备了大容量的 SSD 或 NVMe 硬盘用于快速缓存,以及高速网络接口卡(如 25G/100G 网卡)。
- 软件栈:服务器上运行着专门的缓存软件,如开源的 Varnish Cache、Nginx、Apache Traffic Server,或者 CDN 厂商自研的高性能缓存引擎(如 Cloudflare 的 Workers)。这些软件不仅负责缓存和响应请求,还集成了访问控制、协议优化、日志记录等功能。
3.2 全局负载均衡系统(GSLB - Global Server Load Balancer)
GSLB 是 CDN 的“大脑”,负责在成千上万个边缘节点中,为每一个用户请求选出“最优”的节点。
- 核心功能:
- 健康检查:持续探测各边缘节点的可用性(是否宕机、网络是否可达),将故障节点从调度列表中剔除。
- 负载监控:实时收集各节点的 CPU、内存、带宽、连接数等负载信息,避免将流量导给过载节点。
- 地理/运营商感知:根据用户 Local DNS 的 IP 地址,识别用户所属的国家、地区、城市以及网络运营商,尽可能选择同地域同运营商的节点(例如,北京联通的用户优先分配给北京联通的 CDN 节点)。
- 性能探测:部分高级 CDN 会通过主动探测(如发送探测包)或被动探测(分析用户与节点间的实际通信延迟、丢包率)来评估用户到各节点的网络质量。
- 实现方式:GSLB 最常见的实现方式是基于 DNS 的调度。CDN 为客户的域名提供一个 CNAME 记录,指向 CDN 厂商的某个域名(如
www.example.com.cdn.example.com)。当用户请求解析时,请求会到达 CDN 的权威 DNS 服务器,该服务器集成了 GSLB 逻辑,根据上述因素动态返回一个最佳的边缘节点 IP。
[[TABLE_PLACEHOLDER_1]] (建议表格:对比DNS调度、Anycast路由、HTTP重定向三种调度方式的原理、优缺点)
| 调度方式 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| DNS 调度 | 权威DNS根据LDNS IP返回不同IP | 实现简单、兼容性好、对用户透明 | 调度粒度粗(基于LDNS IP)、无法感知实时负载、DNS缓存影响时效性 |
| Anycast | BGP路由将流量导向拓扑最近的节点 | 天生负载均衡、高可用、抗DDoS | 基于网络层,无法感知应用层负载,可能导致流量倾斜 |
| HTTP 重定向 | 入口节点返回302响应,指向最优节点 | 调度精细(基于真实IP和实时负载) | 增加一次RTT延迟,适用于对首次延迟不敏感的场景 |
3.3 缓存系统
缓存系统是 CDN 的核心存储组件,决定了内容的存储、检索和更新效率。
- 存储层次:为了平衡成本和性能,CDN 缓存通常采用多层架构。
- 内存(RAM):热数据(频繁访问的内容)存储在内存中,以提供纳秒级的访问速度。常用的缓存软件如 Varnish 主要依赖内存。
- SSD/HDD:温数据和冷数据存储在 SSD 或 HDD 上。SSD 提供了良好的读写性能,HDD 则适合大容量存储(如视频文件)。
- 缓存键(Cache Key):用于唯一标识一个缓存对象的键值。默认情况下,缓存键通常由请求的 Host 头部、URL 路径和查询字符串组成。但 CDN 允许用户自定义缓存键,例如忽略某些无关紧要的参数(如
?utm_source=google),以提高缓存命中率。 - 内容索引:缓存系统需要维护一个快速的内存索引(如哈希表),用于根据缓存键定位存储介质上的内容位置。当请求到达时,首先查询索引,若存在则从对应位置读取数据并返回。
3.4 内容管理系统
内容管理系统是客户与 CDN 交互的“控制台”,用于管理内容的发布和更新。
- 内容注入(预热):客户可以通过 API、控制台或 FTP 等方式,将静态资源预先上传(预热)到 CDN 节点,确保首次访问的用户也能获得快速体验。这在电商大促等场景下至关重要。
- 内容刷新/清除(Purge):当源站内容更新时,客户需要通知 CDN 删除或更新旧缓存。刷新可以是精确的 URL、目录级别,甚至是通配符匹配。CDN 收到刷新指令后,会通过内部消息通知全网所有节点删除指定缓存,后续请求将重新回源获取最新内容。
- 预取(Prefetch):CDN 可以根据算法预测即将被访问的内容(如网页中链接的下一页),并在用户请求之前主动将其从源站拉到边缘节点,进一步降低延迟。
3.5 监控与日志系统
一个健壮的 CDN 离不开全面的监控与日志分析。
- 实时监控:监控各节点的流量、带宽、请求数、缓存命中率(Cache Hit Ratio)、回源率、响应时间等关键指标。一旦指标异常(如回源率飙升),系统会触发告警,提示运维人员介入。
- 访问日志:边缘节点会详细记录每一次用户请求的日志,包括时间、客户端 IP、请求 URL、响应状态码、响应大小、处理时间、缓存状态(HIT/MISS)等。这些日志被汇聚到大数据平台,用于生成报表、分析用户行为、计费以及优化调度策略。
4. CDN 的工作流程详解
本节将通过几个典型的场景,深入剖析 CDN 的工作流程,包括用户首次访问、缓存命中、缓存未命中以及动态内容的处理。
4.1 用户请求流程: DNS 调度主导
假设源站域名为 origin.example.com,网站已接入 CDN,用户访问 http://cdn.example.com/index.html。
- DNS 解析开始:用户浏览器向本地配置的 DNS 服务器(LDNS)发起查询,询问
cdn.example.com的 IP 地址。 - CNAME 解析:
cdn.example.com的权威 DNS 服务器(假设由域名托管商管理)配置了一条 CNAME 记录,指向example.cdn.com。因此,LDNS 收到响应:“你需要去查询example.cdn.com”。于是 LDNS 转而查询example.cdn.com。 - CDN 权威 DNS 介入:
example.cdn.com的权威 DNS 服务器由 CDN 服务商管理。这个服务器集成了 GSLB 逻辑。它收到了来自 LDNS 的查询请求,其中包含了 LDNS 的 IP 地址(如202.96.134.133)。 - GSLB 决策:CDN 的 GSLB 模块基于以下信息进行决策:
- 地理/运营商信息:通过 IP 库查询得知 LDNS 位于中国北京,属于中国联通。
- 节点健康状态:检查北京联通节点的 CDN 服务器是否健康。
- 节点负载:获取当前北京联通节点的负载情况(连接数、CPU 使用率等)。
- 网络性能(可选):如果有历史探测数据,可能会参考该 LDNS 到各候选节点的 RTT(往返时间)。
综合这些因素,GSLB 从北京联通节点池中选择了一个最优的 IP 地址,例如123.125.81.12。
- 返回最终 IP:CDN 权威 DNS 服务器将
123.125.81.12作为查询结果返回给 LDNS。 - IP 传递与连接:LDNS 将
123.125.81.12返回给用户浏览器。浏览器向该 IP 发起 HTTP/HTTPS 连接,请求/index.html。
至此,用户的请求成功被导向了最合适的 CDN 边缘节点。
4.2 缓存命中与未命中
- 缓存命中(HIT):边缘节点收到
/index.html的请求后,立即在本地缓存中查找。如果找到且内容尚未过期(TTL 有效),节点直接从内存或磁盘读取该文件,并组装 HTTP 响应(状态码 200 OK,通常会附带一个X-Cache: HIT的自定义头部)返回给用户。整个过程在节点内部完成,极快。 - 缓存未命中(MISS):如果缓存中没有
/index.html,或者内容已过期,则进入“回源”流程。边缘节点作为 HTTP 客户端,向源站origin.example.com发起一个相同的请求(请求头可能经过修改,如添加Via头部标识这是 CDN 的回源请求)。源站返回index.html文件给边缘节点。边缘节点根据返回头中的缓存控制指令(如Cache-Control: max-age=600)决定将其缓存 600 秒,然后将文件返回给用户(状态码 200 OK,头部可能包含X-Cache: MISS)。用户感知到的延迟会比命中时长,因为它包含了回源的 RTT 和源站处理时间。
4.3 缓存内容更新与一致性维护
保持源站与 CDN 节点内容的一致性是一个关键问题。主要策略如下:
- 基于 TTL 的被动失效:这是最基础的方式。源站通过 HTTP 响应头中的
Cache-Control: max-age或Expires告诉 CDN 内容可以缓存多久。在 TTL 内,CDN 不会回源检查更新。TTL 过期后,下一个请求会触发回源验证。如果内容未变(通过If-Modified-Since或ETag),源站返回 304 Not Modified,CDN 可以续期缓存;如果已变,源站返回新内容并更新缓存。这种方式简单可靠,但无法做到实时更新。 - 主动刷新(Purge/Invalidate):当源站内容发生变更,且需要立即在全球所有节点生效时(例如紧急修复一个错误的图片),客户可以通过 CDN 管理控制台或 API 发起刷新请求。CDN 平台会通过内部消息系统(如 Kafka 或自研的分布式广播),通知所有边缘节点删除指定的缓存对象。后续请求将强制回源获取最新内容。
- 版本号/指纹策略:这是一种更优雅的主动更新方式。在构建静态资源(如
style.css、app.js)时,将其文件名与文件内容的哈希值关联起来(例如style.a1b2c3.css)。当内容更新时,哈希值改变,文件名也随之改变。用户请求新的文件名,自然无法从 CDN 命中旧缓存,从而实现了无感知的平滑更新。这种方式无需刷新 CDN 缓存,是静态资源更新的最佳实践。
4.4 动静分离处理与动态加速
传统的 CDN 擅长加速静态内容,但现代网站越来越多地包含动态内容(如个性化 API、实时数据)。CDN 也演进出了动态加速(DSA,Dynamic Site Accelerator)能力。
- 静态内容加速:如上所述,核心在于缓存。对于图片、CSS、JS、视频等不常变化的文件,CDN 通过大规模缓存实现极速访问。
- 动态内容加速:动态内容无法缓存(或只能缓存极短时间),每次请求都必须到达源站。CDN 在动态加速中扮演的角色是“网络优化器”:
- 路由优化:CDN 拥有遍布全球的节点网络,它们之间通过专线或优化的公网路径互联。当用户请求动态 API 时,CDN 节点不会直接通过公网路由到源站,而是利用其内部网络,选择一条“最佳路径”(如避开拥塞的国际链路)将请求转发到离源站最近的 CDN 节点(称为“回源节点”),再由该节点与源站通信。这被称为“多跳加速”或“路由优化”。
- 协议优化:CDN 节点到源站的连接可以复用长连接、启用 TCP 优化参数(如更大的拥塞窗口)、使用 HTTP/2 多路复用等,减少连接建立和慢启动的开销。
- 连接复用:多个用户的动态请求可以通过 CDN 节点与源站之间的同一个 TCP 连接发送,减少了源站维护大量连接的负担,也提升了传输效率。
- SSL/TLS 加速:CDN 可以负责处理与用户之间的 TLS 握手(卸载证书),然后通过安全的内部网络(或重新加密)将请求转发给源站,减轻了源站的 CPU 消耗。
通过动静分离和动态加速,CDN 可以为整个网站提供“全站加速”的解决方案。
5. 调度系统:如何将用户导向最佳节点
调度系统是 CDN 实现“就近访问”承诺的关键。它必须快速、准确、智能地做出决策。
5.1 DNS 调度(最常见)
如前所述,DNS 调度是目前应用最广泛的方式。其核心是 CDN 的权威 DNS 服务器具备智能解析能力。
- 工作原理:CDN 权威 DNS 服务器不是简单地返回一个固定的 IP,而是根据请求来源(LDNS IP)和预设策略,动态选择 IP 返回。
- 优势:实现简单,对用户透明,兼容性好。
- 局限性:
- 调度粒度粗:它基于 LDNS IP 而不是用户真实 IP。在一个大型 ISP 内,LDNS 可能部署在省级或核心节点,无法精确反映用户真实的地理位置。
- 无法感知实时负载和网络质量:传统的 DNS 调度通常是“静态”的,只根据 IP 归属进行映射,无法感知节点当前的负载或网络拥塞情况。
- DNS 缓存:LDNS 和用户操作系统都会缓存 DNS 结果,TTL 设置过短会增加 DNS 查询量,设置过长则无法及时调整调度。
5.2 Anycast 路由
Anycast(任播)是一种网络寻址和路由方法,它将同一个 IP 地址同时分配给多个不同的节点。当用户向这个 IP 发送数据包时,BGP 路由协议会自动将数据包路由到“拓扑距离最近”(通常是根据 BGP 路由算法,如 AS 跳数最少)的那个节点。
- 工作原理:CDN 将同一个 IP 地址块(例如一个 /24 段)宣告到全球多个数据中心的路由器上。当用户访问该 IP 时,互联网的骨干路由器会根据自身的路由表,选择一条最短路径将数据包转发到其中一个数据中心。
- 优势:
- 天生负载均衡:流量被自然地分散到最近的节点。
- 高可用性:当一个节点宕机,BGP 路由会自动收敛,将流量切换到其他可用节点,对用户几乎无感。
- DDoS 防护:分布式攻击流量会被分散到多个节点,避免单点被击垮。
- 局限性:Anycast 的路由决策完全由网络层决定(基于 BGP 的 AS 路径长度),无法感知应用层的负载和应用层延迟。可能导致流量集中到某个节点,即使该节点负载已高。
5.3 HTTP 重定向调度
这是一种应用层的调度方式,通常与 DNS 调度结合使用作为补充。
- 工作原理:用户首先通过 DNS 解析到一个固定的入口节点。该节点收到 HTTP 请求后,根据自身负载情况、用户 IP 等信息,判断出更合适的节点,然后返回一个 HTTP 302(或 307)重定向响应,在
Location头中给出新的节点域名或 IP。用户浏览器会重新向新节点发起请求。 - 优势:调度决策可以非常精细,可以基于实时的负载、RTT、甚至用户 Cookie 中的信息。由于是在应用层,可以获取用户的真实 IP。
- 局限性:引入了额外的 RTT(一次重定向),增加了首次访问的延迟。适用于对首次延迟不敏感或需要精细调度的场景。
5.4 综合决策因素
一个现代 CDN 的 GSLB 系统通常不会依赖单一因素,而是采用多维度评分模型。决策时可能考虑的因素包括:
- 地理邻近性:用户(或 LDNS)与节点之间的物理距离或行政区域(国家、省、市)。
- 网络邻近性:用户与节点之间经过的自治系统(AS)跳数,或者 BGP 的路径长度。
- 实时网络质量:通过主动探测(如每秒从节点向用户段的代表性 IP 发送探测包)获取的 RTT、丢包率、抖动等数据。
- 节点负载:当前节点的 CPU 使用率、内存使用率、并发连接数、出口带宽占用率。
- 成本因素:不同运营商、不同地区的带宽成本可能不同,调度系统可能在性能相近的情况下优先选择成本更低的节点。
- 内容位置:如果请求的内容已经在某个节点有缓存,调度系统可能会优先将该用户导向该节点(“一致性哈希”或“亲和力路由”),以提高缓存命中率。
- 合规性要求:某些内容可能受法律法规限制,只能由特定区域的节点提供服务。
调度系统会周期性(如每分钟)计算各候选节点的综合得分,选择一个最优节点返回给用户。
6. 缓存策略与内容管理
缓存是 CDN 的价值核心,如何高效地存储、索引和更新内容是决定 CDN 性能和成本的关键。
6.1 HTTP 缓存控制协议
CDN 严格遵守 HTTP/1.1 定义的缓存控制标准,这些标准由源站通过响应头指定。
Cache-Control:这是现代 HTTP 缓存控制的首选头部。常用指令包括:max-age=秒:指定内容可以被缓存的最长时间(从请求时刻算起)。例如max-age=3600表示缓存 1 小时。s-maxage=秒:专门用于共享缓存(如 CDN)的指令,优先级高于max-age。源站可以用它来告诉 CDN 缓存多长时间,同时允许浏览器使用不同的缓存时间。private:指示内容只能被单个用户缓存(如浏览器),不允许 CDN 等共享缓存缓存。public:显式指示内容可以被任何缓存缓存(即使响应通常被认为是私有的,如带有身份验证的)。no-cache:字面意思容易误解。它并非禁止缓存,而是强制缓存在使用已缓存内容前,必须向源站发送请求进行“新鲜度验证”(如使用If-Modified-Since)。如果源站返回 304,则仍可使用缓存。no-store:真正的禁止缓存。要求 CDN 不得以任何形式存储该响应。must-revalidate:当缓存过期后,必须向源站验证才能使用;如果无法连接源站,则必须返回 504 错误,而不能直接使用过期内容。
Expires:HTTP/1.0 的头部,指定一个绝对的过期时间点(HTTP 日期)。优先级低于Cache-Control的max-age。Last-Modified与If-Modified-Since:源站可以在响应中包含Last-Modified(最后修改时间)。当 CDN 需要验证缓存是否新鲜时,可以在请求中包含If-Modified-Since头部,值为之前记录的Last-Modified。如果内容在该时间之后未修改,源站返回 304 Not Modified,CDN 可以续用缓存。ETag与If-None-Match:ETag是源站为内容生成的唯一标识符(通常是文件内容的哈希值)。验证时,CDN 在请求中包含If-None-Match: [ETag值]。如果内容未变,源站返回 304;如果已变,返回新内容(200)和新ETag。ETag比Last-Modified更精确(可以精确到秒内多次修改)。
6.2 缓存键的设计
默认情况下,缓存键由请求的 Host、URL 路径和查询字符串组成。例如,对 https://cdn.example.com/style.css?version=1 的请求,缓存键可能是 cdn.example.com/style.css?version=1。但这会带来一个问题:如果 version 参数只是用于防止缓存(一种常见但错误的做法),那么不同的 version 值会导致同一份内容被缓存多次,浪费存储空间并降低命中率。
因此,CDN 允许自定义缓存键,常用的优化包括:
- 忽略指定查询参数:配置忽略
utm_系列、sessionid等不影响内容的参数。 - 缓存键包含特定头部:有时内容可能因
Accept-Encoding(压缩方式)或User-Agent(设备类型)而异,需要将这些头部纳入缓存键。 - 规范化缓存键:将 URL 进行规范化处理,如小写化、去除多余的斜杠等,避免因细微差异导致缓存不命中。
6.3 缓存淘汰算法
CDN 节点的存储空间是有限的。当存储空间写满时,需要淘汰一些旧内容来为新内容腾出空间。常用的淘汰算法包括:
- LRU(Least Recently Used,最近最少使用):淘汰最长时间没有被访问的内容。这是最常用的算法,因为它符合访问的局部性原理(最近被访问过的内容,将来很可能再次被访问)。实现方式通常是将缓存内容按访问时间组织成链表,每次访问将内容移到链表头,淘汰时从链表尾删除。
- LFU(Least Frequently Used,最不经常使用):淘汰访问频率最低的内容。这有助于保留虽然访问间隔长但总次数多的“经典”内容。实现较为复杂,需要维护访问计数。
- FIFO(First In First Out,先进先出):淘汰最早进入缓存的内容。实现简单,但效果通常不如 LRU 和 LFU。
- 混合策略:实际 CDN 中常采用混合策略,例如结合 TTL 过期和 LRU。过期内容优先被淘汰,当空间不足时再淘汰 LRU 中较老的内容。
6.4 内容预热与刷新
- 预热:在重大活动(如电商大促、新游戏发布)前,客户可以通过 CDN 的预热功能,提前将大量资源(如商品图片、游戏安装包)主动分发到全球边缘节点。预热完成后,海量用户首次访问时即可命中缓存,避免瞬间回源流量冲垮源站。
- 刷新:当源站内容更新或出现错误时,需要刷新 CDN 缓存。刷新可以是精准的 URL,也可以是目录(如刷新
/images/下的所有文件)。CDN 平台需要将刷新指令可靠地广播到所有节点,并确认节点已执行删除操作。这是一个高并发的分布式任务,对系统的最终一致性有很高要求。
6.5 分层缓存
为了进一步提高缓存命中率和降低回源压力,大型 CDN 通常采用多级缓存架构:
- L1 Edge(边缘层):最靠近用户的节点,数量最多,分布最广。它们负责直接响应用户请求,缓存容量相对较小(如 SSD),主要缓存热数据。
- L2 Mid-tier(中层/区域层):位于边缘层和源站之间,数量较少,通常部署在核心数据中心。它们拥有更大的存储容量(如 HDD 集群),作为边缘层的“后备缓存”。当边缘节点未命中时,它不是直接回源,而是先向中层节点请求。如果中层节点有缓存,则返回给边缘节点,这被称为“回源命中”。只有中层节点也未命中时,才会最终回源。
这种分层架构可以极大地减少对源站的请求,同时让边缘层可以缓存更多的热数据。它类似于 CPU 的 L1/L2/L3 缓存设计。
[[IMG_PLACEHOLDER_2]] (建议配图:分层缓存架构图,展示用户 -> L1边缘节点 -> L2中层节点 -> 源站的请求流程)
7. CDN 的安全功能
随着网络安全威胁日益严峻,CDN 凭借其分布式架构和巨大的带宽资源,逐渐成为网站安全防护的第一道防线。
7.1 DDoS 防护
分布式拒绝服务攻击(DDoS)旨在通过海量垃圾流量耗尽目标服务器或网络带宽,使其无法服务合法用户。CDN 天然具备抵御 DDoS 的能力。
- 网络层 DDoS 防护:
- 流量清洗:所有流量首先到达 CDN 节点。CDN 会在网络入口处部署流量清洗设备(或利用其路由器的能力),实时监控流量特征。一旦检测到异常流量(如 UDP Flood、ICMP Flood、SYN Flood),会立即将其引流到“清洗中心”,通过特征匹配、限速、指纹验证等方式过滤掉恶意流量,只将干净流量转发给源站。
- Anycast 扩散:对于采用 Anycast 的 CDN,攻击流量会被分散到全球多个节点,每个节点只承受一部分攻击压力,使得攻击者很难通过单点流量耗尽目标。Cloudflare 的“无容量上限” DDoS 防护正是基于此原理。
- 应用层 DDoS 防护:
- HTTP Flood 防护:应用层攻击更难防御,因为它们看起来像是正常的 HTTP 请求。CDN 通过行为分析来识别恶意请求,例如:统计单个 IP 的请求频率(QPS)、分析 User-Agent 是否合法、检查请求路径是否正常、进行 JavaScript 挑战验证(计算题或 CAPTCHA)以区分浏览器和僵尸程序。对于异常高频的 IP,可以进行临时封禁或限速。
7.2 Web 应用防火墙(WAF)
WAF 用于保护 Web 应用免受 OWASP Top 10 等常见漏洞的攻击,如 SQL 注入、跨站脚本(XSS)、跨站请求伪造(CSRF)、文件包含漏洞等。
- 工作原理:WAF 通常以反向代理模式部署在 CDN 节点上,对经过的 HTTP/HTTPS 请求和响应进行深度检测。
- 规则匹配:WAF 内置了成千上万条安全规则,这些规则由安全专家编写,用于匹配恶意攻击的典型载荷(如
' OR '1'='1用于 SQL 注入,用于 XSS)。当请求或响应内容匹配到规则时,WAF 可以采取阻断、记录、告警等动作。 - 自定义规则:用户可以根据自身业务特点,编写自定义规则,例如:只允许特定国家的 IP 访问后台管理页面;阻止访问特定敏感路径(如
/wp-admin);对登录接口实施更严格的限流等。 - 机器学习:高级 WAF 还利用机器学习模型,通过分析正常业务流量特征,自动学习并建立基线,从而能够识别并拦截未知的、0-day 漏洞的攻击尝试。
7.3 访问控制
CDN 提供了丰富的访问控制功能,帮助内容提供商保护其内容不被滥用或盗用。
- IP 黑白名单:允许或禁止特定 IP 地址或 IP 段的访问。常用于内部系统访问、抵御特定来源的攻击。
- Referer 防盗链:检查 HTTP 请求头中的
Referer字段,只有来自允许的域名(白名单)的请求才能获取资源。这常用于防止其他网站直接引用图片、视频等资源,盗取流量。但 Referer 容易被伪造,因此安全性有限。 - User-Agent 黑白名单:允许或禁止特定客户端(如某些爬虫、老旧浏览器)的访问。
- 时间戳防盗链 / Token 鉴权:这是一种更安全的访问控制机制。内容提供商生成一个包含过期时间、客户端 IP(可选)、资源路径的令牌(通常通过 MD
本文由主机测评网发布,不代表主机测评网立场,转载联系作者并注明出处:https:///yunfuwuqi/9487.html
