
大模型深度学习:Ucloud、腾讯云、阿里云GPU服务器横向评测
最近人工智能领域热度持续攀升,各类大模型、AIGC应用层出不穷,直接导致“AI炼丹”所需的硬件成本水涨船高。许多热门显卡在京东等电商平台长期处于缺货状态,甚至加价也一卡难求。想要搭建一台能够流畅跑深度学习模型的个人工作站,随便一套配置下来动辄两三万元,这对于学生、独立开发者或中小团队而言,是不小的经济压力。
低成本跑深度学习模型,或者需要进行模型训练,租用云服务器依然是目前最务实的省钱方案。 深度学习云服务器的核心硬件在于显卡,当前市场基本被英伟达(NVIDIA) 垄断,不同型号在架构、显存、算力及适用场景上存在显著差异。为帮助读者建立系统性认知,我们先对英伟达三大产品线进行深度拆解:
Quadro系列:Quadro系列显卡(现部分已升级为RTX专业版)主要面向特定垂直行业,如建筑工程、工业设计、影视后期等。其特点是经过ISV(独立软件供应商)认证,驱动对AutoCAD、SolidWorks、Maya等专业软件有深度优化,但在深度学习通用计算场景下,与同代消费级显卡相比并无额外优势,且价格昂贵,因此不推荐作为入门深度学习的主力选择。
GeForce系列:该系列定位消费级市场,是游戏玩家的首选。得益于庞大的用户群,CUDA生态适配成熟,许多个人开发者使用RTX 3090/4090等显卡进行模型训练,性价比突出。但需要注意:消费级显卡通常不支持ECC显存纠错,在长时间高负荷科学计算中出现数据错误的概率略高于专业卡;且部分型号(如RTX 4060/4070)显存位宽被削减,对大批量数据训练有一定限制。
Tesla系列:这是本文重点推荐的数据中心专用计算卡。Tesla系列针对7×24小时高负载计算场景设计,具备ECC显存纠错、更高的计算密度和更大的显存容量。典型代表如NVIDIA V100(Volta架构) 和 NVIDIA T4(Turing架构)。V100最早引入Tensor Cores,极大加速矩阵运算,至今仍是许多科研机构的主力卡;T4则主打低功耗与通用性,支持FP16/INT8等精度推理,广泛用于线上AI服务。
下面我推荐的这几款深度学习服务器,均为各大云厂商官方渠道公开售卖或通过活动释放给广大AI炼丹用户的机型,基础性能、网络延迟、数据安全均有专业团队保障,可放心使用。
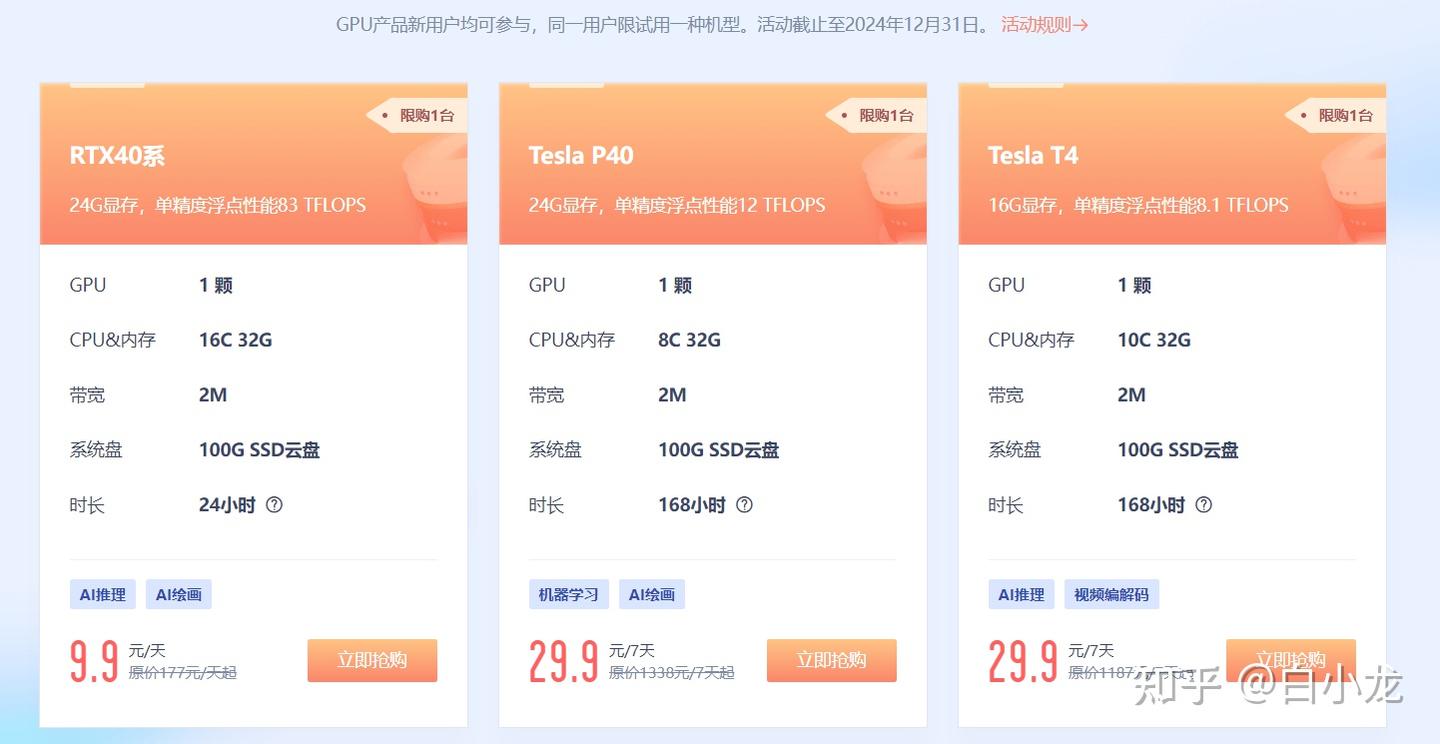
Ucloud —— 极致性价比的入门之选
Ucloud家的GPU服务器可能正是许多小伙伴一直在寻找的“梦中情机”——价格亲民,配置不妥协。其主打短期灵活租赁模式,最低仅需9.9元/天即可体验GPU算力,另有29.9元/7天的尝鲜套餐。若项目周期较长,还可选择30天包月配置,价格依然远低于市场平均水平。
在硬件配置上,Ucloud提供英伟达V100和P系列(如P4/P40) 显卡。V100拥有16GB/32GB HBM2显存,支持NVLink高速互联,适合中型以上模型训练;P4/P40虽架构稍老,但显存大(P40 24GB GDDR5),对于部分对显存要求高但对延迟不敏感的任务(如批量推理)仍是高性价比选择。
适用场景:算法验证、个人学习、短期竞赛、初创团队原型开发。
专家建议:如果你是学生或刚入门深度学习,强烈建议先从Ucloud的7天短期套餐入手。9.9元一天的成本甚至低于一杯奶茶,却能让你在真实环境下跑通第一个模型。务必留意活动机型是否包含公网IP带宽费用,部分特价套餐需单独购买带宽。
腾讯云——GPU计算型 GN10Xp(V100旗舰之选)
GPU计算型 GN10Xp 是腾讯云面向高性能计算推出的实例规格,单实例搭载1颗NVIDIA Tesla V100(高端版32GB显存)。V100至今仍是深度学习领域的“中流砥柱”,其采用的Volta架构首次引入针对深度学习的Tensor Cores,可大幅加速混合精度训练。
市场背景:前两个月,国内头部大模型开发团队在市场上大规模扫货V100,导致现货奇缺,二手市场价格一度飙升。目前市面流通的多为零散库存,腾讯云作为头部云厂商,凭借供应链优势仍有稳定供货,这一点尤为可贵。
核心算力指标解析:
- 半精度(FP16):112 TFLOPS —— 适合混合精度训练,可显著提升训练速度并降低显存占用。
- 单精度(FP32):14 TFLOPS —— 常规单精度计算标准,绝大多数模型的基础运行精度。
- 双精度(FP64):7.5 TFLOPS —— V100罕见地在计算卡中保留了较高双精度算力,适用于部分需要高精度计算的科学仿真任务。
- Tensor性能:120 TFLOPS —— 这是V100作为深度学习专用卡的核心优势,专为矩阵乘加运算设计,训练Transformer、BERT等模型效率极高。
实战案例:笔者近期使用GN10Xp实例部署Stable Diffusion WebUI,并微调LoRA模型。实测生成一张512×512像素的图片,耗时约30秒至1分钟(视采样步数、模型复杂度及ControlNet使用情况)。以电商场景为例:上传一件服装商品图,通过LoRA快速生成不同姿态、不同背景的虚拟模特上身效果图,模型响应迅速,显存占用稳定在12GB-18GB之间,V100 32GB版本游刃有余。对于NLP任务,如BERT微调、GPT系列轻量化训练,该机型同样表现出色,训练速度与显存容量均无明显瓶颈。
目前腾讯云对GN10Xp推出482元/7天的活动机,不限新老用户,是体验旗舰V100算力的极佳入口。
腾讯云——GPU服务器 GN7(T4均衡之选)
腾讯云GPU服务器 GN7搭载1颗NVIDIA Tesla T4显卡。T4基于Turing架构,虽定位略低于V100,但在功耗控制、视频编解码、INT8推理方面表现突出。
性能数据:
- 半精度(FP16):65 TFLOPS
- 单精度(FP32):8.1 TFLOPS
- INT8精度:130 TOPS —— 专为低延迟推理优化,部署生产级AI服务时成本优势明显。
T4技术亮点:
1. RT Cores:支持光线追踪,虽然深度学习不直接使用,但在结合神经渲染的前沿研究中存在应用潜力。
2. 多精度推理:T4对INT4/INT8等低精度量化支持完善,配合TensorRT加速库,可在保持模型精度的前提下将推理速度提升数倍。
3. 显存与功耗:16GB GDDR6显存,功耗仅70W,无需主动散热,云厂商部署密度高,因此租用成本更低。
适用场景:中小规模模型训练、实时图像识别、语音识别、推荐系统在线推理。目前腾讯云GN7活动价265元/7天,同样不限新老用户。对于预算有限且对算力要求并非顶配的用户,T4是目前性价比最高的平衡点。
注意事项:T4在训练大语言模型(百亿参数级)时显存和算力均显不足,建议将其定位为推理卡或轻量级训练卡。
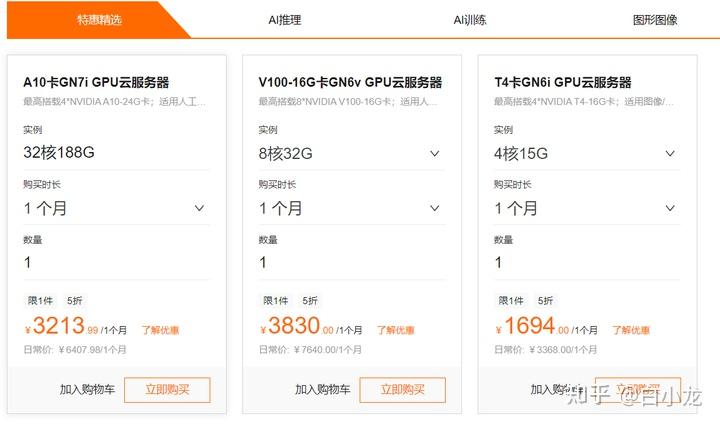
阿里云——系列GPU云服务器(灵活扩展之选)
阿里云开放的系列GPU服务器,在核心显卡上与腾讯云产品线多有对应,但策略差异显著:
- 搭载V100的GPU服务器(如gn6v规格族):目前公开目录价约3830元/月。相比之下,腾讯云30天活动价为1698元,价格优势明显。
- 搭载Tesla T4的GN6i GPU云服务器:目前约1694元/月,而腾讯云同期活动低至60元/15天,短期使用成本远低于阿里云。
阿里云的核心优势在于定制化与扩展性:腾讯云活动机多为固定套餐,实例规格、显卡数量、存储及带宽均为预配置,无法修改。阿里云支持按需自由配置,若项目需要多卡并行(如2卡、4卡甚至8卡V100/T4),可通过控制台自定义增加显卡数量。这对于分布式训练、大规模模型并行的用户至关重要。
专家建议:若你的模型需要跨节点多卡通信,阿里云的高性能计算集群及RDMA网络支持更为成熟,尽管单价略高,但整体训练效率更高。对于需要长期稳定运行的大团队,建议关注阿里云的预留实例券或节省计划,相比按量付费可降低30%-50%成本。
各厂商主流型号的算力、显存、价格及适用场景
| 厂商/实例规格 | 显卡型号 | 核心架构 | 显存容量/类型 | 关键算力指标 | 参考价格 | 网络性能 | 核心优势 | 适用场景/人群 |
|---|---|---|---|---|---|---|---|---|
| Ucloud(GPU云主机) | NVIDIA V100 或 P4/P40 | Volta (或 Pascal) | 16GB HBM2 (V100) 或 24GB GDDR5 (P40) | FP16: 112 TFLOPS FP32: 14 TFLOPS | 9.9元/天起 (29.9元/7天) | 常规万兆 | 极致低价、 按天短租、 入门门槛极低 | 学生、个人开发者、 算法验证、短期竞赛、 原型开发 |
| 腾讯云GN10Xp | NVIDIA V100(高端版) | Volta | 32GB HBM2(支持ECC) | FP16: 112 TFLOPS Tensor: 120 TFLOPS | 482元/7天(活动价) | 高并发 低延迟 | 超大显存、 旗舰算力、 适合大模型微调 | 中型训练、 Stable Diffusion、 BERT微调、 高性能计算 |
| 腾讯云GN7 | NVIDIA T4 | Turing | 16GB GDDR6 | FP16: 65 TFLOPS INT8: 130 TOPS | 265元/7天(活动价) | 均衡型 | 能效比高、 推理加速强、 视频编解码 | 在线推理、 轻量训练、 实时识别、 推荐系统 |
| 阿里云gn6v | NVIDIA V100 | Volta | 16GB HBM2 | FP16: 112 TFLOPS FP32: 14 TFLOPS | 约3830元/月(目录价) | 支持RDMA | 多卡扩展、 集群部署、 自定义配置 | 长期项目、 企业级研发、 多卡并行训练 |
| 阿里云GN6i | NVIDIA T4 | Turing | 16GB GDDR6 | FP16: 65 TFLOPS INT8: 130 TOPS | 约1694元/月(目录价) | 常规万兆 | 灵活升降配、 生态完善 | 标准化服务、 中小规模推理 |
表格解读与选购决策树
看预算与周期:
短期尝鲜(<7天):首选 Ucloud(9.9元/天)或 腾讯云GN7(性价比极高)。
中期项目(1-3个月):首选 腾讯云GN10Xp,V100 32GB显存在处理高清图片生成、13B级别模型微调时具备不可替代的优势。
看任务类型:
训练为主:优先考虑 V100 系列。其Tensor Cores对矩阵运算的加速效果远非传统CUDA核心可比。
推理为主:首选 T4 系列。T4支持的INT8精度在不明显损失模型精度的情况下,可将吞吐量提升数倍,长期运行更省电费。
看扩展需求:
若未来明确需要2卡、4卡甚至8卡并行,请直接考虑阿里云。腾讯云活动机多为“固定套餐”,不支持跨卡扩展,而阿里云支持自定义规格,且在高性能计算集群中提供RDMA(远程直接数据存取) 网络,这是多机多卡训练效率的关键保障。
专家提示:表格中的“参考价格”多为特定活动或目录价,实际下单时请以官网实时报价为准。购买前务必确认是否包含公网带宽,部分特价机需单独购买IP和流量包,这往往是隐藏成本所在。
总结
经过上述对比,当前深度学习GPU云服务器市场呈现明显的分层供给格局:
Ucloud凭借极致低价和灵活短租模式,大幅降低了普通用户接触GPU算力的门槛。虽然品牌声量不及头部大厂,但核心硬件(V100/P4)均为正品,适合学生、个人开发者及预算敏感的小微团队。
腾讯云通过限时活动,将旗舰V100和高性价比T4以极具竞争力的价格开放给全体用户(不限新老),是中短期项目的首选。如果你需要稳定、开箱即用且无需额外运维成本的方案,腾讯云活动机是目前市场的“价格屠夫”。
阿里云的优势在于高度定制化和多卡扩展能力。当你的任务从单卡训练升级为多卡并行甚至多机多卡时,阿里云完善的云产品矩阵(如CPFS并行文件系统、高性能调度器)可以提供更坚实的底层支撑。当然,为此你需要支付更高的溢价。
未来趋势:随着算力普惠化浪潮,云厂商正逐步将存量V100、T4资源通过短期活动释放,预计未来两年推理成本将进一步下降。同时,国产GPU(如寒武纪、昇腾)在特定场景的适配性逐步提升,未来云服务器市场将呈现更多元的选择。对于开发者而言,关注厂商活动、熟悉不同精度的算力转换、学会利用竞价实例,将是长期控制成本的关键技能。
最终决策:
- 轻度试用、预算极低 → Ucloud 9.9元/天套餐
- 短期项目、追求综合性能 → 腾讯云 GN10Xp(V100)
- 推理为主、注重性价比 → 腾讯云 GN7(T4)
- 长期大规模、多卡并行 → 阿里云 自定义配置
无论选择哪家,都建议先小额测试,确认网络带宽、数据迁移成本及售后服务响应速度后再批量采购。希望这份指南能助你在AI炼丹路上,算力自由,灵感不熄。
本文由主机测评网发布,不代表主机测评网立场,转载联系作者并注明出处:https://zhuji.jb51.net/ceping/9575.html
