
B站日志系统
B站的日志系统(Billions)从2017年5月份开始建设,基于elastic stack,面向全站提供统一的日志采集、检索、监控服务。目前集群规模20台机器,接入业务200+,单日日志量10T+。
借此机会跟大家分享一些B站在日志系统的建设、演进以及优化的经历。由于经验尚少,抛砖引玉,欢迎大家一起交流讨论。文章主要分为三个部分:原有日志系统,现有系统演进,未来的展望。
原有日志系统
在Billions之前,B站内部并没有统一的日志平台,基本是业务之间各自为战,既有基于ELK的比较前瞻的方式,又有服务器上使用tail/grep比较基本原始的方式,水平参差不齐。在了解各个产品线的情况后,存在的问题和诉求主要有以下几点:
- 方案各异。 由于各个部门自行实现日志方案,没有专人维护,普遍存在维护成本高、系统不稳定、丢日志、易用性不足的情况。
- 业务日志没有统一的规范。业务日志格式各式各样,导致最直接的问题就是无法按照统一的规则对日志进行切分,这无疑大大的增加了日志的分析、检索成本。
- 对PAAS支持不好。公司内部正在大面积推广应用容器化,但是并没有一个好的日志方案支撑容器内应用日志的采集。
- 日志利用程度低。对于日志的利用程度普遍停留于日志检索的水平,受限于工具未对日志的价值进行进一步挖掘,例如:日志监控、统计分析、调用链分析。
针对上述问题,提出新的日志系统的设计目标如下:
- 业务日志平滑接入:业务日志接入日志系统,只需要进行简单的配置;日志平台也只需要进行一些基本的配置,无须涉及日志内容等业务信息。
- 多样性支持:环境多样:物理机(虚拟机)、容器;来源多样:系统日志、业务日志、中间件日志……;格式多样:单行/多行, plain/json。
- 日志挖掘:快速可查,日志监控,统计分析。
- 系统可用性:数据实时性;丢失率可控(业务分级、全链路监控)。
Billions的演进
系统的初建
日志规范
为了解决业务日志格式多样性问题,统一制定了日志格式规范,使用JSON作为日志的输出格式。
格式要求:
- 必须包含四类元信息:
- time: 日志产生时间,ISO8601格式
- level:日志等级, FATAL、ERROR、WARN、INFO、DEBUG
- app_id:应用id,用于标示日志来源,与公司服务树一致,全局唯一
- instance_id:实例id,用于区分同一应用不同实例,格式业务方自行设定
- 日志详细信息统一保存到log字段中。
- 除上述字段之外,业务方也可以自行添加额外的字段。
- json的mapping应保持不变:key不能随意增加、变化,value的类型也应保持不变。
例如:
{"log": "hello billions, write more", "level": "INFO", "app_id": "testapp111", "instance_id": "instance1", "time": "2017-08-04T15:59:01.607483", "id": 0}
日志系统技术方案
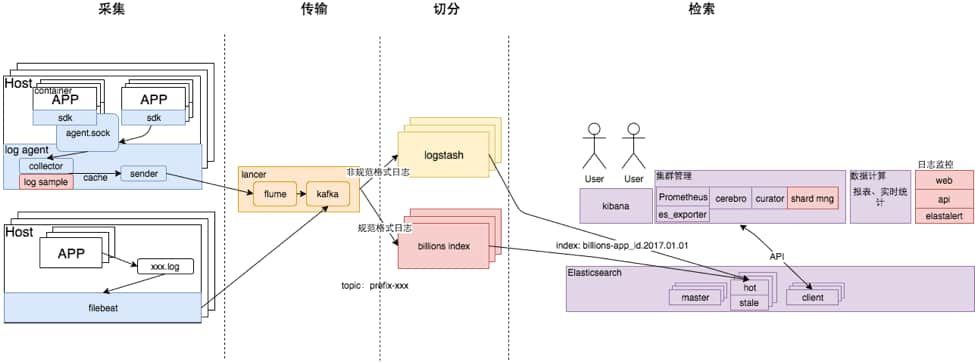
日志从产生到消费,主要经历以下几个阶段:采集->传输->切分->检索。
日志采集
日志采集针对非落盘和落盘两种方式。
- 对于业务模块日志,统一按照日志规范并且通过非落盘的方式进行输出。针对此类场景,与平台技术部合作,基于go我们开发了log agent模块。

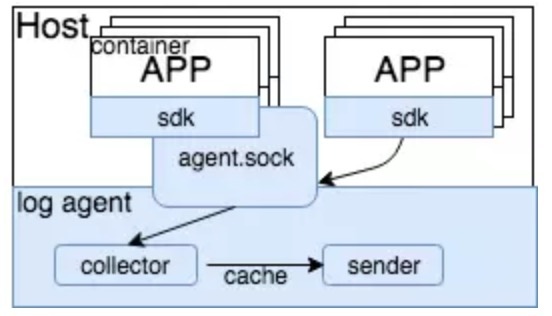
- log agent部署在物理机上,暴露出一个domain sock文件,程序将日志通过unixgram方式输出到domain sock。
- 对于运行在PAAS上的应用,在container初始化的时候,sock文件被默认mount到container内部,这样容器内的程序就可以输出日志。
- log agent分为两个部分,collector和sender。collector用于接收日志,sender用于向传输系统发送日志。两者直接通过一个文件缓存进行交互。这样在日志传输系统故障的情况下,依赖本地缓存可以保证日志的正常接收。
- 我们提供了不同语言对应的日志库(sdk),程序可以快速接入日志系统。
- 非业务模块(中间件、系统模块、接入层)日志,由于定制化能力较差,我们通过读取生成的日志文件完成日志的采集。
- 我们采用的elastic stack中的filebeat进行采集,filebeat具有方便部署、配置简单、资源消耗低的优势,而且支持多行日志的拼接。
- 物理机上部署一个单独的filebeat进程,每一类日志对应一个单独的配置文件。
- 每一条日志都会被单独打上一个app_id标签,这个类似业务日志的app_id字段,这样在最终消费日志的时候就可以进行区分了。
- filebeat会自动标示日志来源机器,这样也就具有了区分同一应用不同实例的能力。
日志采集
公司内部已经有了统一的数据传输平台(lancer),lancer的优势如下:
- 基于flume+kafka做二次定制化开发,内部自动负载均衡,容量可水平扩展。
- 数据接收端实现了一套可靠的数据传输协议,完善的链路监控,数据传输安全可靠。
- 可以根据业务需要对接不同的消费方式(kafka、hdfs)。
- 有专业的团队进行7*24维护。
因此我们直接选择lancer作为我们的日志传输系统。
- log agent中的sender模块基于lancer的定制化的数据传输协议发送日志,最终日志被传输到kafka集群中的不同topic(根据日志流量,配置topic),后续从kafka消费日志,所有的topic采用一个统一的prefix。
- 由于暂时没有精力对filebeat进行二次定制化开发,因此filebeat直接将日志输出到lancer的kafka集群。
日志切分
日志切分模块的主要作用是从kafka消费日志,对日志进行处理(字段提取、格式转换),最终存储到elasticsearch的对应的index中。我们使用logstash作为我们的日志切分方案。
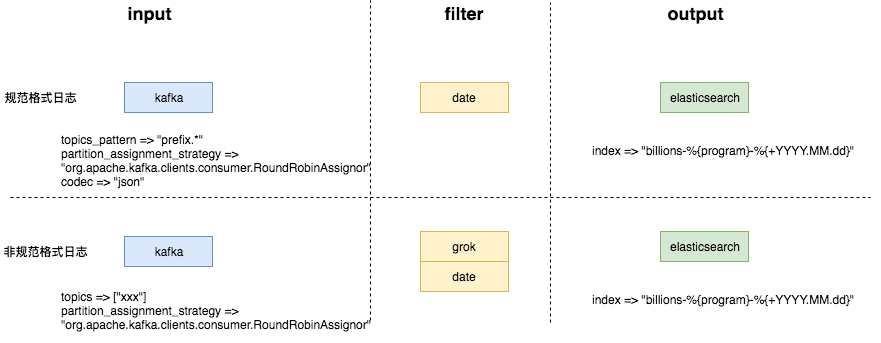
其中:
- 对于按照日志规范生成的日志,日志的kafka topic采用了统一的前缀,因此我们采用topics_pattern的方式来消费日志。
- logstash的partition_assignment_strategy要设置为”org.apache.kafka.clients.consumer.RoundRobinAssignor”,默认的策略(Range partitioning)会导致partition分配不均,如果采用默认的策略,当consumer(logstash数量*worker数量)的数量大于topic partition数量时,partition总是只会被分配给固定的一部分consumer。
- 对于非标准格式日志,由于logstash single event pipeline的限制,因此缺乏对于多配置的支持(期待6.0的multi event pipeline)。每种日志配置不同,因此需要单独的logstash进程进行消费。
日志检索
elasticsearch集群规模为:master node*3, hot node*20, stale node*20,client node*2。es版本为5.4.3,集群配置如下:
- 数据机器(40core,256G内存, 1T ssd, 6T*4 SATA)采用冷热分离的方案:同时部署一个hot node和stale node。hot node使用ssd作为存储介质,接收实时日志。stale node使用sata盘作为存储介质,存储历史日志(只读不写)。每日固定时间进行热->冷迁移。
- client node对外提供读取api,对接kibana、管理程序(比如curator、cerebro等)。
- index管理(迁移、删除)采用curator,日志默认保留7天。
- es集群配置优化借鉴了很多社区的建议,就不详细介绍了。
- 使用template进行index mapping的管理。
- index提前一天进行创建,防止集中创建导致数据无法写入。
- es监控:调研了官方的x-pack monitor,由于x-pack monitor功能不足(例如缺少对于线程池的监控),并且不能进行报警,最终选择自研。公司内部监控系统基于Prometheus,我们开发了es_exporter负责采集es的状态信息,最终监控报警通过Prometheus实现。报警主要包含关键指标,例如:es cluster的状态信息、thread rejected数量、node节点数量、unassign shard数量。
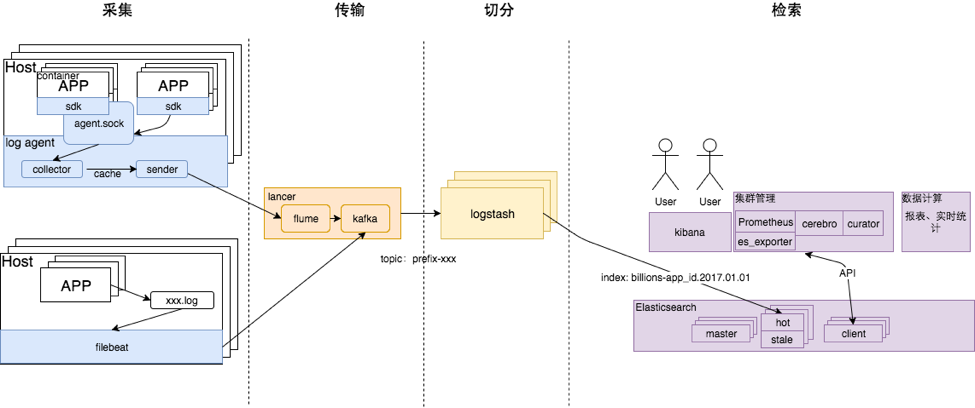
经过上述步骤,最终日志就可以在kibana上进行查询。第一阶段,日志系统的整体架构为:
系统迭代
随着接入的日志量越来越大,渐渐出现一些问题和新的需求,Billions主要在以下方面进行了升级迭代。
shard管理
最初采用了es默认的管理策略,所有的index对应5*2个shard(5个primary,5个replica),带来的主要问题如下:
- 每个shard都是有额外的开销的(内存、文件句柄),大部分的index的数量都比较小,完全没有必要创建5个shard。
- 某些index的数据量很大(大于500GB/day),单个shard对应的数据量就会很大,这样会导致检索的速度不是最优, 并且磁盘write IO集中在少数机器上。
针对上述问题,开发了index管理模块(shard mng),根据index的历史数据量(昨日数据),决定创建明日index对应shard数量,目前策略为30GB/shard,shard数量上限为15。通过以上优化,集群shard数量降低了70%+,磁盘IO使用也更加高效。
日志采样
某些业务的日志量很大(大于500GB/day),多为业务的访问日志,对日志而言,“大量数据中的一小部分就足以进行问题排查和趋势发现”,与研发和运维进行沟通,这个观点也得到认同。
因此在数据采集源头log agent(collector模块)中增加了日志采样(log sample)功能:
- 日志采样以app_id为维度,INFO级别以下日志按照比例进行随机采样,WARN以上日志全部保留。
- log agent接入公司配置中心,采样比例保存在配置中心,可以动态生效。
- 有个细节额外说明下:由于要获取日志内的app_id字段,如果直接进行json解析, cpu消耗将非常之高。后续我们改进为字符查找(bytes.Index ),解决了这个问题。
针对日志量大的业务进行采样,在不影响使用的情况下,节省了大量的es资源。目前每天减少3T+的日志写入。
data node硬件瓶颈解决
晚上20:00-24:00是B站业务的高峰期,同时也是日志流量的高峰期。随着流量的增长,经常收到日志延迟的报警(日志没有及时的写入es),通过观察监控,主要发现两个现象:
- hot node出现了较多bulk request rejected,同时logstash收到了很多的429响应。尝试调大了thread pool size和 queue_size,但是问题依然存在。
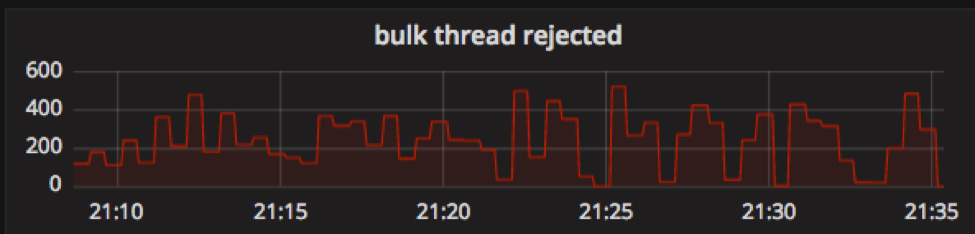
- hot node机器长时间出现io wait现象,同时SSD Disk io Utiliztion 100% 。
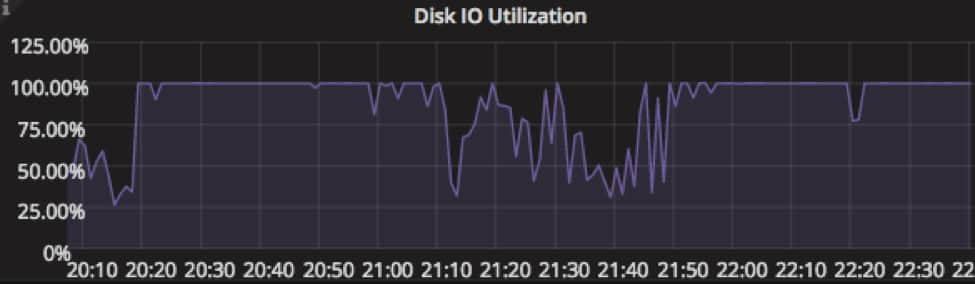
通过以上现象,怀疑是SSD IO不足导致的es写入拒绝。后续对SSD进行了性能测试和对比,发现此型机器上SSD的写性能较差。为了减少SSD IO压力,我们将一部分实时写流量迁移到了stale node(stale node之前不接受实时写流量,写入压力很小),日志延迟的问题暂时得以解决。
终极解决办法:data node的机型为40 core CPU,256G内存,1T SSD+4*6T SATA,很明显此机型SSD从性能和容量上都是瓶颈,为了提升此机型的利用率和解决SSD IO性能瓶颈,最终我们为每台机器添加了2*1.2T pcie SSD,一劳永逸!
logstash性能解决
在解决了上述es写入瓶颈后,过了一段时间,高峰期日志延迟的问题又出现了。这次es并没有出现bulk request rejected的问题。 从整条链路进行排查,日志收集和日志传输上都没有出现日志延迟的现象,最终把注意力放在了日志切分模块(logstash)。
logstash性能差是社区内公认的,进一步针对logstash进行性能测试,在(2 core+4G memory)情况下,不断调整worker数量和pipeline.batch.size, 极限性能为8000qps,性能的确很差,高峰期的流量为40W/s, 因此至少需要50个logstash实例才能满足要求,显然这样的资源消耗无法接受。考虑到业务日志对应的切分功能较为单一,因此我们使用go自研了日志切分模块(billions index)。
自研的模块性能有了很大的提升,2 core+4G memory条件下,极限性能提升到5w+qps,并且内存只消耗了150M。 线上的资源消耗从(2 core+4G memory) 30 减少到了(2 core+150M memory)15,性能问题也得到解决。
日志监控
随着越来越多的业务的接入,日志监控的需求越来越强烈。目前社区的解决方案中,Yelp的elastalert最为成熟,功能丰富,并且也方便进行进一步的定制化。因此我们选择基于elastalert实现日志监控。
结合自身需求,通过查看文档和阅读代码,elastalert也有一些不足之处:
- rule存储在文件中,不可靠并且无法进行分布式扩展。
- rule配置比较复杂,不够友好和易用。
- 程序单点,高可用无法保证。
- 监控规则顺序执行,效率低(如果所有规则执行时间大于执行间隔,单条规则的定期执行将无法保证)。
针对上述不足和自身需要,我们对于elastalert进行了二次开发:
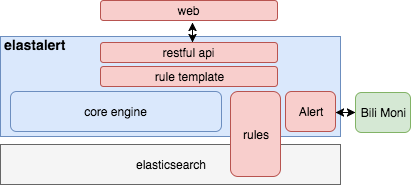
主要的改进点包括:
- 将所有的rule存储在elasticsearch中,即增加了rule存储的可靠性,也为elastalert的分布式实现做好准备。
- 所有类型的日志监控rule使用模板进行封装,以降低配置复杂度。例如限制使用query string过滤日志,屏蔽某些配置项等等。
- 封装出一套Restful api进行监控规则的增删改查。
- 与公司现有监控系统(Bili Moni)结合:基于web配置日志监控,通过报警平台发送报警。
- 利用全局锁解决单点问题:两个进程一热一冷,热进程故障后冷会自动接手,并进行报警。
- 对于报警内容进行了调整(格式调整,汉化),表述更加清晰。
日志监控1.0目前已经投入使用,并且还在持续迭代。
最新Billions的架构如下:
现有问题和下一步工作
目前日志系统还存在很多不足的地方,主要有:
- 缺乏权限控制:目前权限控制缺失,后续需要实现统一认证、基于index的授权、操作审计等功能,类比xpack。
- 缺乏全链路监控:日志从产生到可以检索,经过多级模块,目前监控各层独立实现,未进行串联,因此无法对堆积和丢失情况进行精准监控。
- 日志监控性能瓶颈:目前日志监控为单节点(一个热节点工作)并且规则顺序执行,后续需要优化为分布式架构+规则并行执行。
- 日志切分配置复杂:对于非标准格式日志,基于logstash实现日志切分,每一种日志需要单独的logstash实例进行消费,配置和上线过程复杂,后续需要平台化的系统进行支撑。
[转自:https://mp.weixin.qq.com/s?src=11×tamp=1508813953&ver=471&signature=27pv3pR30wWO6CZ6PZLCLXX3KYHFl5eAJ-TLXUCp3OitIhBMX7qlkNveejLvX7V-6RuG8UutPnknpFRctW70L6RSnVxp-oaZGMZUsZE5FepfNQRjZ50m5u60BaW8vtSG&new=1]
本文由主机测评网发布,不代表主机测评网立场,转载联系作者并注明出处:https://zhuji.jb51.net/yunwei/8345.html
