
awk分组求和分组统计次数
作者:服务器运维 • 更新时间:2023-05-21 •
分组求和
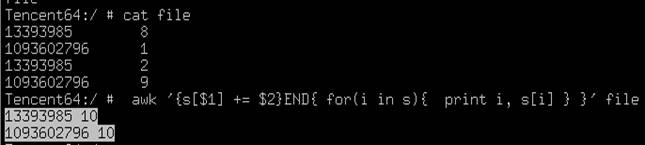
awk '{s[$1] += $2}END{ for(i in s){ print i, s[i] } }' file1 > file2以第一列 为变量名 第一列为变量,将相同第一列的第二列数据进行累加打印出和.
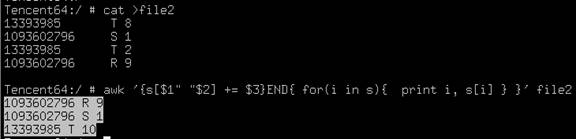
awk '{s[$1" "$2] += $3}END{ for(i in s){ print i, s[i] } }' file1 > file2以第一列和第二列为变量名, 将相同第一列、第二列的第三列数据进行累加打印出和
awk '{s[$1] += $2; a[$1] += $3 }END{ for(i in s){ print i,s[i],a[i] } }' haha.txt如果第一列相同,则根据第一列来分组,分别打印第二列和第三列的和

匹配
1、匹配交集项
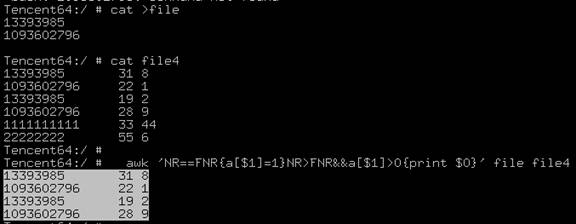
awk 'NR==FNR{a[$1]=1}NR>FNR&&a[$1]>0{print $0}' file1(字段:QQ) file2(字段:QQ 点券值 ) > file3如果file1、file2中,2个文件的第一列值相同,输出第2个文件的所有列
注意:数据量如果达到4Gb以上或者行数达到一亿级别,建议将file2进行split分割,否则就算是32G的内存的机器都会被吃掉;
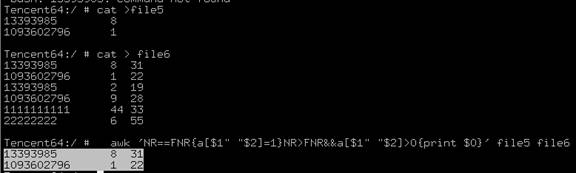
awk 'NR==FNR{a[$1" "$2]=1}NR>FNR&&a[$1" "$2]>0{print $0}' file1 file2> file3如果file1、file2中,2个文件的第一列第二列值相同,输出第2个文件的所有列
2、匹配非交集项
awk 'NR==FNR{a[$1]=1}NR>FNR&&a[$1]<1 {print $0}' file1 file2 > file3针对2个文件的第一列做比较,输出:在file2中去除file1中第一列出现过的行
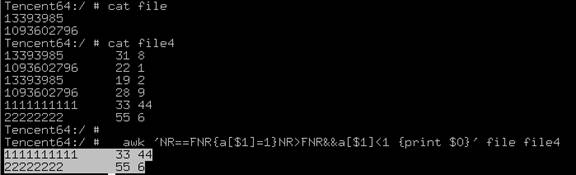
第二种方法:
cat file1 file2|sort |uniq -d > jiaoji.txt cat file2 jiaoji.txt |sort |uniq -u > file3
取最大值、最小值
1、针对(2列的文件)
awk '{max[$1]=max[$1]>$2?max[$1]:$2}END{for(i in max)print i,max[i]}' file第一列不变,取第二列分组最大值
awk '{if(!min[$1])min[$1]=20121231235959;min[$1]=min[$1]<$2?min[$1]:$2}END{for(i in min)print i,min[i]}' file第一列不变,取第二列分组最小值
2、针对单列的文件
awk 'BEGIN {max = 0} {if ($1>max) max=$1 fi} END {print "Max=", max}' file2
awk 'BEGIN {min = 1999999} {if ($1<min) min=$1 fi} END {print "Min=", min}' file2
求和、求平均值、求标准偏差
求和
cat data|awk '{sum+=$1} END {print "Sum = ", sum}'求平均
cat data|awk '{sum+=$1} END {print "Average = ", sum/NR}'求标准偏差
cat $FILE | awk -v ave=$ave '{sum+=($1-ave)^2}END{print sqrt(sum/(NR-1))}'
整合行和列
1、列换成行
如果第一列相同,将所有的第二列 第三列 都放到一行里面
awk '{qq[$1]=qq[$1](" "$2" "$3)}END{for(i in qq)print i,qq[i]}'
2、合并文件
2个文件,每个2列,将他们按照第一列相同的数,来合并成一个三列的文件,同时,将每个文件中针对第一列对应第二列中没有的数补0
awk 'FNR==NR{a[$1]=$2}FNR<NR{a[$1]?a[$1]=a[$1]" "$2:a[$1]=a[$1]" 0 "$2}END{for(i in a)print i,a[i]}' file1 file2 > file3注意点:文件2 一定要比文件1 的行数小
3、2个文件,每个3列,将他们按照第一列、第二列相同的数,来合并成一个4列的文件,同时,将每个文件中针对第一列、第二列对应第3列中没有的数补0
awk 'FNR==NR{a[$1" "$2]=$3}FNR<NR{a[$1" "$2]?a[$1" "$2]=a[$1" "$2]" "$3:a[$1" "$2]=a[$1" "$2]" 0 "$3}END{for(i in a)print i,a[i]}' file4、将列换成行,遇到空行,另起下一行
awk 'begin {RS=""} {print $1,$2,$3} file15、某列数字范围筛选
cat canshu |while read a b
do
awk '{ if ($2>'"$a"' && $2<='"$b"' ) print $1}' result.txt > "$a"_"$b"_result.log
done注意点:awk使用函数时,使用'"$a"'(先单引号,后双引号)
集合类

1、集合交
cat fileA fileB |sort |uniq –d > result.log
2、集合差
cat fileA fileB |sort |uniq -d > jiaoji.txt cat fileA jiaoji.txt |sort |uniq -u > result.log
3、集合全集去重
cat fileA fileB |sort -u > result.log
4、集合全集不去重
cat fileA fileB |sort > result.log
本文由主机测评网发布,不代表主机测评网立场,转载联系作者并注明出处:https://zhuji.jb51.net/yunwei/8028.html
